
CS 3100: Program Design and Implementation II
Lecture 15: Test Doubles and Isolation
©2025 Jonathan Bell, CC-BY-SA
Learning Objectives
After this lecture, you will be able to:
- Distinguish between unit, integration, and end-to-end tests
- Explain the challenge of testing code with external dependencies
- Identify properties of high-quality individual tests (hermetic, clear, non-brittle)
- Differentiate between stubs, fakes, and spies as types of test doubles
- Apply mocking frameworks to generate test doubles
- Evaluate the tradeoffs of using test doubles
- Apply AI coding assistants to generate test plans and test doubles
What Makes a Good Test Suite?
Fast, reliable, and finds bugs—and individual tests must be hermetic, clear, and non-brittle.
🎯
Finds Bugs
Actually detects defects in the code
🔒
Is Reliable
Passes when code is correct, fails when it's not
⚡
Is Fast
Runs quickly so you actually run it
Suite goals
- Find bugs
- Run automatically
- Be cheap to run
Individual tests
- Hermetic
- Clear + debuggable
- Not brittle (avoid unspecified behavior)
- Use public APIs only
⚡ What Makes Tests Fast (or Slow)?
I/O dominates—memory is microseconds, network is milliseconds.
Think about it: what operations take time in a test?
Fast (microseconds)
- Creating objects in memory
- Calling methods
- Arithmetic, string operations
Slow (milliseconds to seconds)
- File system I/O
- Network calls (APIs, databases)
- Starting processes/containers
🔒 What Makes Tests Reliable (or Flaky)?
Control all state → deterministic. Depend on external world → flaky.
A "flaky" test sometimes passes, sometimes fails — same code!
Reliable (deterministic)
- Same inputs → same outputs
- No shared mutable state
- No timing dependencies
Flaky (non-deterministic)
- Network timeouts
- Race conditions
- External service state
Empirical studies find a few causes dominate flakiness (Luo et al., FSE 2014):
Async wait / timeouts: ~37%
Test order dependency: ~17%
Concurrency: ~17%
Resource leaks: ~10%
Network: ~9%
Other: floating point, random, unordered collections
🎯 Measuring Bug-Finding: Coverage
Coverage measures what code ran, not whether it's correct.
Code coverage measures what code your tests execute
Statement coverage: % of lines executed
Branch coverage: % of decision paths taken (if/else, loops)
But coverage has a fatal flaw...
Coverage Can Still Miss Bugs
100% branch coverage ≠ 100% tested behaviors.
Even 100% branch coverage does not mean you tested every behavior.
public int magic(int x, int y) {
int z;
if (x != 0) { z = x + 10; }
else { z = 0; }
if (y > 0) { return y / z; } // BUG: can divide by zero
else { return x; }
}
@Test void t1() { assertEquals(2, magic(1, 22)); } // covers x!=0, y>0
@Test void t2() { assertEquals(0, magic(0, -10)); } // covers x==0, y<=0
// 100% branch coverage… but magic(0, 5) throws ArithmeticException
Where Do Test Inputs Come From?
Spec-driven and code-driven strategies complement each other.
Two fundamental strategies for choosing test inputs:
Spec-Driven
(from requirements)
- What should the code do?
- Boundary values, equivalence classes
- "2 cups → should convert to 32 tbsp"
Code-Driven
(from implementation)
- Look at branches, paths
- Choose inputs to exercise each path
- Coverage guides what's missing
AI-assisted (new reality): ask for equivalence classes + boundaries… then you validate the oracle.
Example-Based Testing: What You Know
You choose specific inputs from requirements or by examining code.
You write specific test cases with specific inputs
@Test
void shouldConvert2CupsTo32Tablespoons() {
ExactQuantity twoCups = new ExactQuantity(2, Unit.CUP);
Quantity result = twoCups.convertTo(Unit.TABLESPOON, registry);
assertThat(result.getAmount()).isEqualTo(32); // 2 cups × 16 tbsp/cup
}
You choose inputs from requirements or by examining the code
Parameterized Tests: Same Logic, Many Inputs
Write the test logic once; run it with many inputs.
From the HW3 handout — test the same behavior with different data
static Stream<Arguments> toStringTestCases() {
return Stream.of(
Arguments.of(1, "Preheat oven", "1. Preheat oven"),
Arguments.of(2, "Mix ingredients", "2. Mix ingredients"),
Arguments.of(10, "Serve warm", "10. Serve warm"),
Arguments.of(99, "Final step", "99. Final step"));
}
@ParameterizedTest(name = "step {0}: \"{1}\" -> \"{2}\"")
@MethodSource("toStringTestCases")
void shouldFormatCorrectly(int stepNumber, String text, String expected) {
Instruction instruction = new Instruction(stepNumber, text, List.of());
assertThat(instruction.toString()).isEqualTo(expected);
}
Property-Based Testing: Describe Properties, Generate Inputs
Describe invariants; let the framework find counterexamples.
JUnit-QuickCheck (out of scope for this class, but worth knowing about)
@Property
void scalingPreservesRatios(
@ForAll @IntRange(min=1, max=100) int flour,
@ForAll @IntRange(min=1, max=100) int sugar,
@ForAll @DoubleRange(min=0.1, max=10) double scaleFactor) {
Recipe original = recipeWith(flour, sugar);
Recipe scaled = original.scale(scaleFactor, registry);
// Property: ratio of flour:sugar should be preserved
double originalRatio = flour / (double) sugar;
double scaledRatio = getFlour(scaled) / (double) getSugar(scaled);
assertThat(scaledRatio).isCloseTo(originalRatio, within(0.001));
}
Framework generates hundreds of random inputs satisfying constraints
Fuzzing: Generate LOTS of Inputs
Generate millions of inputs to find crashes you'd never imagine.
Automatically generate inputs to find crashes and bugs
Graybox Fuzzing (used by security researchers):
- Start with sample inputs, randomly mutate them
- Monitor code coverage to guide mutation
- If mutation covers new code → keep it, mutate further
- Run millions of inputs per second
Google's OSS-Fuzz has found 10,000+ bugs in open-source projects
The Testing “Vibe” Trap
Passing tests + high coverage ≠ tests that detect bugs.
The failure mode looks just like “vibe coding” (L13), but for tests:
- Ask AI to generate tests
- Tests pass, coverage goes up
- Ship it
The problem: many generated tests have weak oracles, duplicate coverage (many tests checking the same thing), or are flaky/brittle.
Strong Oracles Beat More Tests
A test is only as good as its oracle.
A test oracle is the rule that decides when a test should fail.
Weak oracles
- “It doesn’t crash”
- “Result is not null”
Overuse of
any()/ vague verifications
Strong oracles
- Exact expected output
- All observable effects verified
- Meaningful properties + boundaries checked
The Tradeoff Triangle
Fast + Reliable vs. Finds Real Bugs—different tests make different tradeoffs.
Now we see the challenge: these goals conflict!
| ⚡ Fast | 🔒 Reliable | 🎯 Finds Real Bugs | |
|---|---|---|---|
| Test in memory only | ✓ | ✓ | Maybe misses I/O bugs |
| Test with real services | ✗ | ✗ | ✓ Catches integration bugs |
Different test types make different tradeoffs
Unit Tests: ⚡ Fast + 🔒 Reliable
Test one unit in isolation: fast, focused, deterministic.
Test a single "unit" — typically one class — in isolation
⚡ Fast: Run in milliseconds (no I/O, no network)
🔒 Reliable: No external state = deterministic
✓ Focused: When it fails, you know exactly where to look
The challenge: achieving isolation when code has dependencies
Unit Test Example: From HW3 Handout
If it fails, you know exactly where the bug is.
Testing Instruction.toString() — one class, no dependencies
@ParameterizedTest(name = "step {0}: \"{1}\" -> \"{2}\"")
@DisplayName("should format as stepNumber. text")
void shouldFormatCorrectly(int stepNumber, String text, String expected) {
Instruction instruction = new Instruction(stepNumber, text, List.of());
assertThat(instruction.toString()).isEqualTo(expected);
}
// Test cases: (1, "Preheat oven", "1. Preheat oven")
// (2, "Mix ingredients", "2. Mix ingredients")
// (10, "Serve warm", "10. Serve warm")
Integration Tests: The Middle Ground
Test components together to catch seam bugs.
Test multiple components interacting
⚡≈ Moderate speed: Some I/O, but local
🔒≈ Mostly reliable: Controlled environment
🎯✓ Catches seam bugs: Serialization, protocols, formats
Do components communicate correctly? Agree on data formats?
Integration Test Example: From HW3 Handout
Round-trip tests catch serialization and format issues.
Testing Recipe + JsonRecipeRepository + Jackson + file system together
@Test
@DisplayName("round-trip preserves recipe with all fields")
void roundTripPreservesRecipeWithAllFields() {
Recipe recipe = new Recipe("test-id", "Chocolate Cake",
new ExactQuantity(8, Unit.WHOLE),
List.of(new MeasuredIngredient("flour",
new ExactQuantity(2, Unit.CUP), null, null)),
List.of(new Instruction(1, "Mix ingredients", List.of())),
List.of());
repository.save(recipe); // Writes JSON to file system
Optional<Recipe> loaded = repository.findById("test-id");
assertTrue(loaded.isPresent());
assertEquals(recipe, loaded.get());
}
End-to-End Tests: 🎯 Finds Real Bugs
Test the whole system as users experience it—slow but realistic.
Test the entire system as a user would experience it
⚡✗ Slow: Seconds or minutes per test
🔒✗ Flaky: Network glitches, timing issues
🎯✓ Realistic: Tests what users actually experience
The opposite tradeoff: sacrifice speed and reliability for realism
E2E Example: Cook Your Books Import-to-Export
One test, many systems—and many potential failure points.
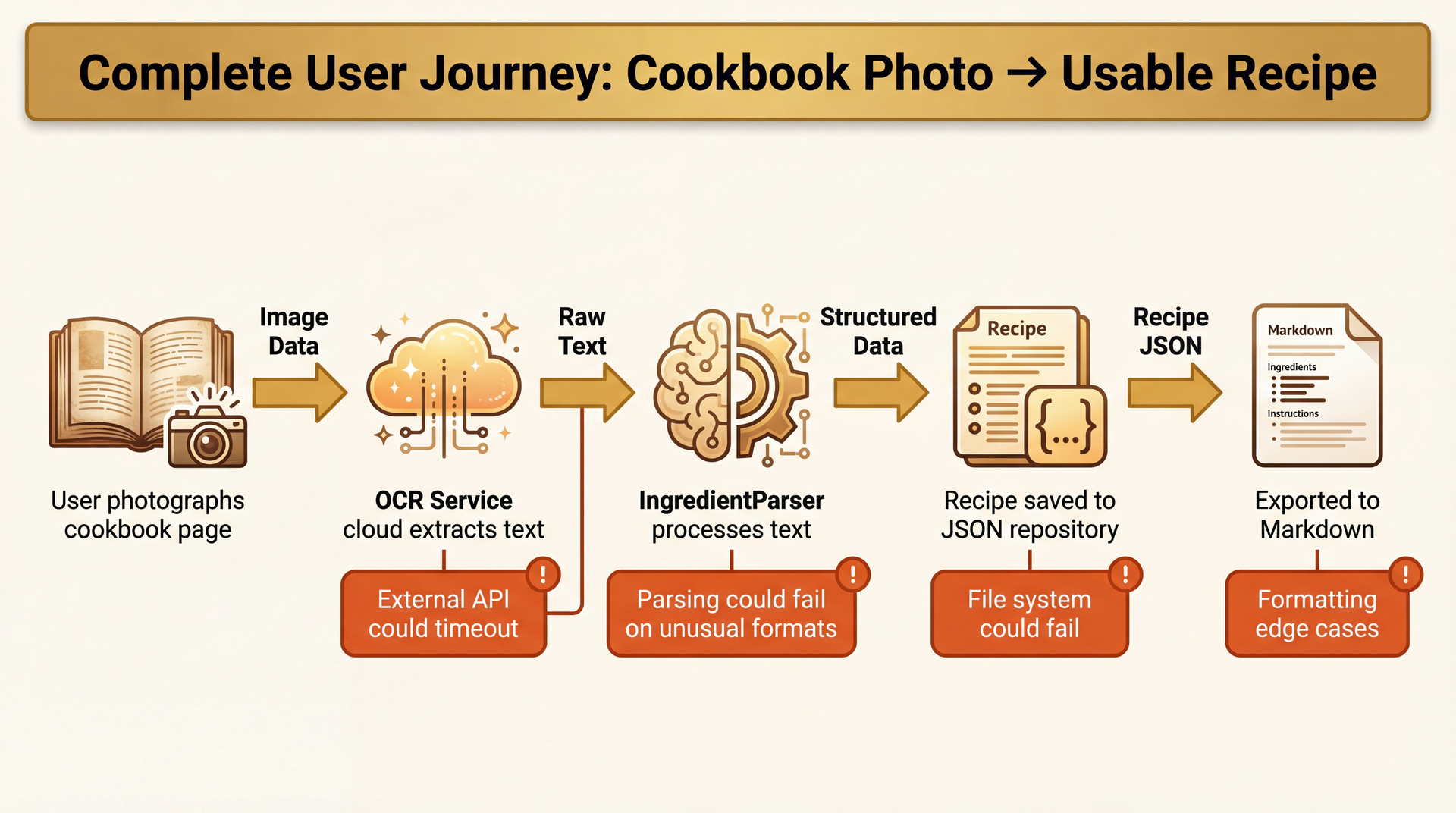
One test, five systems: Image → OCR → Parser → Repository → Exporter
The Practical Mix
E2E tests for critical journeys; unit tests for edge cases.
Why not just write E2E tests for everything?
Imagine testing 15 edge cases for ImportService:
| Unit Tests | E2E Tests | |
|---|---|---|
| Example | ImportService logic | Full OCR-to-export workflow |
| Time to run | ~150ms total | ~30 seconds |
| Flakiness | None | OCR API, file system |
| Debug time | Seconds | Minutes to hours |
The Test Pyramid
Many unit tests, some integration, few E2E.
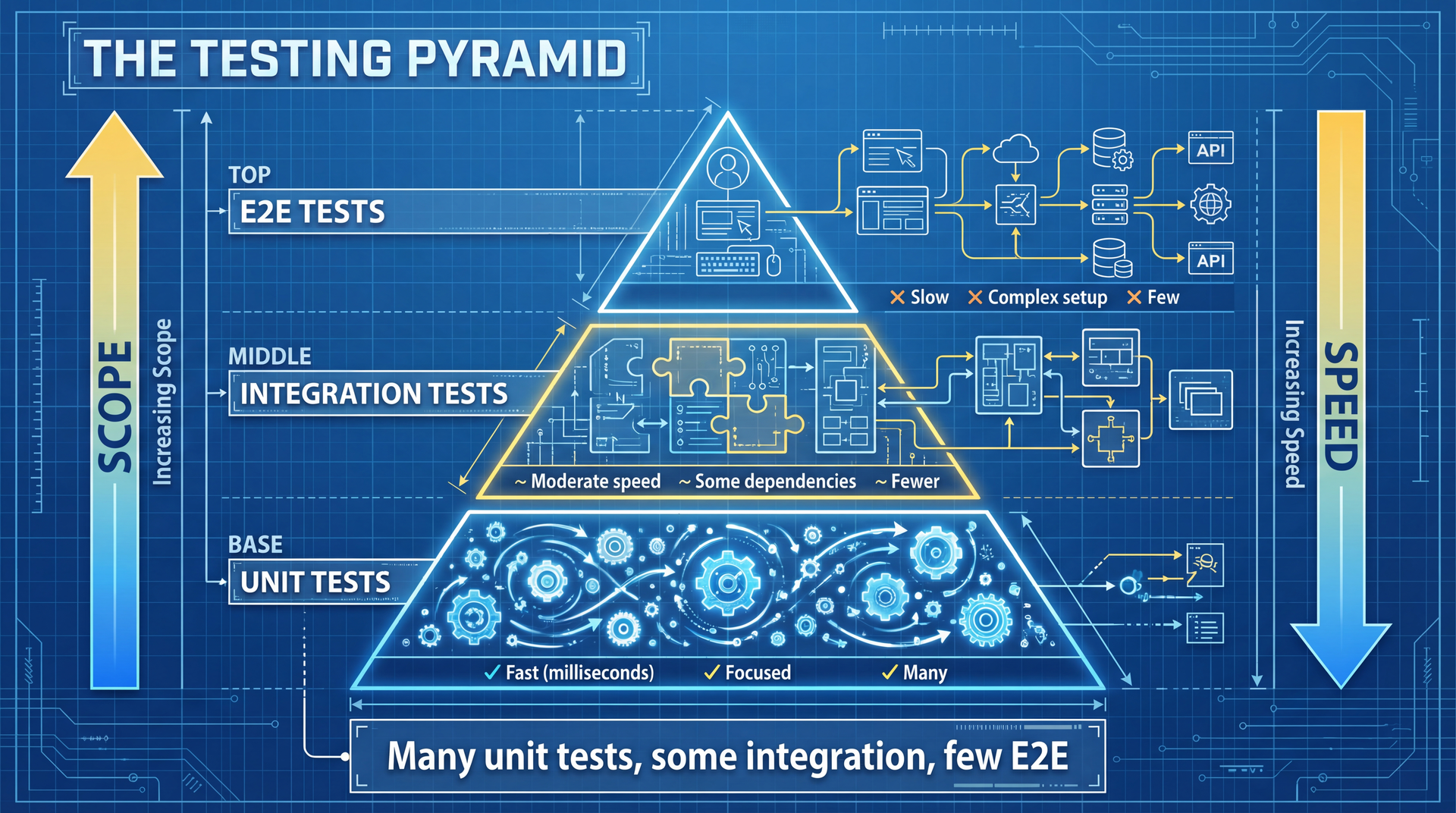
From Big Tests to Small Tests: Find the Seams
Replace dependencies with doubles to carve unit tests from E2E.
Start with a real user workflow, then carve out unit tests by replacing dependencies.
One big test (E2E)
- Slow + flaky (network, DB, timeouts)
- Hard to debug (“something failed”)
- Good for one critical journey
Many small tests (unit)
- Fast + reliable (in-memory)
- Each test targets one behavior/edge case
Depends on test doubles for external services
The trick: identify dependencies (GitHub/API/DB/email) and replace them with stubs/fakes/spies/mocks.
The Dependency Problem
How do we test code that depends on databases, networks, hardware?
Consider SubmissionService from Pawtograder:
public class SubmissionService {
private final GitHubService github;
private final AutograderRunner autograder;
private final NotificationService notifier;
private final Database database;
public SubmissionService(GitHubService github,
AutograderRunner autograder,
NotificationService notifier,
Database database) {
this.github = github;
this.autograder = autograder;
this.notifier = notifier;
this.database = database;
}
// ...
}
The Method Under Test
Testing side effects requires controlling dependencies.
public GradeResult processSubmission(Submission submission) {
CodeSnapshot code = github.fetchCode(submission.repoUrl());
TestResult result = autograder.runTests(code);
if (result.allPassed()) {
database.saveGrade(submission.studentId(), result.score());
notifier.send(submission.studentEmail(),
"Your submission passed!", NotificationLevel.INFO);
} else {
notifier.send(submission.studentEmail(),
"Some tests failed", NotificationLevel.WARNING);
}
return new GradeResult(submission.studentId(), result);
}
To test this, we'd need real GitHub, real containers, real email!
Test Doubles: Stand-Ins for Real Dependencies
Stubs return canned answers; fakes work simply; spies record calls.
Stubs
Return canned answers
Fakes
Simplified implementations
Spies
Record what happened
From simplest to most sophisticated
Stubs: Return Canned Answers
Ignore details you don't care about; return what you need.
class StubGitHubService implements GitHubService {
private final CodeSnapshot fixedCode;
public StubGitHubService(CodeSnapshot code) {
this.fixedCode = code;
}
@Override
public CodeSnapshot fetchCode(String repoUrl) {
return fixedCode; // Always returns the same code
}
}
Ignores the repo URL, always returns sample code — that's fine!
Spies: Record What Happened (Decorator Pattern)
Wrap, record, delegate—verify interactions after the fact.
class SpyDatabase implements Database {
private final Database delegate; // Wraps a real implementation
private boolean saveGradeCalled = false;
private String savedStudentId = null;
public SpyDatabase(Database realDatabase) {
this.delegate = realDatabase; // Decorator pattern!
}
@Override
public void saveGrade(String studentId, int score) {
this.saveGradeCalled = true; // Record the call
this.savedStudentId = studentId;
delegate.saveGrade(studentId, score); // Delegate to real impl
}
// Query methods for tests
public boolean wasSaveGradeCalled() { return saveGradeCalled; }
public String getSavedStudentId() { return savedStudentId; }
}
A Complete Test with Hand-Rolled Doubles
Stubs + spies enable fast, focused tests.
@Test
public void savesGradeWhenAllTestsPass() {
StubGitHubService stubGithub = new StubGitHubService(sampleCode());
StubAutograderRunner stubAutograder = new StubAutograderRunner(
new TestResult(true, 100)); // All tests pass, score 100
SpyDatabase spyDatabase = new SpyDatabase();
StubNotificationService stubNotifier = new StubNotificationService();
SubmissionService service = new SubmissionService(
stubGithub, stubAutograder, stubNotifier, spyDatabase);
service.processSubmission(new Submission("student123", "repo-url", "email"));
assertTrue(spyDatabase.wasSaveGradeCalled());
assertEquals("student123", spyDatabase.getSavedStudentId());
assertEquals(100, spyDatabase.getSavedScore());
}
The Pain of Hand-Rolling Test Doubles
Four classes for one test? That doesn't scale.
We wrote four separate classes just to test one method!
- StubGitHubService
- StubAutograderRunner
- SpyDatabase
- StubNotificationService
And we haven't tested failures, timeouts, edge cases...
Do we need a new stub class for every test result?
Mockito: Test Doubles Without the Boilerplate
Generate test doubles at runtime with when() and verify().
A mocking framework generates test doubles at runtime
@Test
public void savesGradeWhenAllTestsPass() {
// Create test doubles — Mockito generates these at runtime
GitHubService mockGithub = mock(GitHubService.class);
AutograderRunner mockAutograder = mock(AutograderRunner.class);
NotificationService mockNotifier = mock(NotificationService.class);
Database mockDatabase = mock(Database.class);
// Configure stub behavior
when(mockGithub.fetchCode(anyString())).thenReturn(sampleCode());
when(mockAutograder.runTests(any())).thenReturn(new TestResult(true, 100));
SubmissionService service = new SubmissionService(
mockGithub, mockAutograder, mockNotifier, mockDatabase);
service.processSubmission(new Submission("student123", "repo-url", "email"));
// Verify spy recordings
verify(mockDatabase).saveGrade("student123", 100);
verify(mockNotifier).send(eq("email"), contains("passed"), any());
}
Mockito: Create, Configure, Verify
mock(), when().thenReturn(), verify()—the three operations you'll use most.
mock(Class.class) | Create a test double |
when(...).thenReturn(...) | Configure stub behavior |
verify(mock).method(...) | Check spy recordings |
when(...).thenThrow(...) | Simulate exceptions |
Mockito uses reflection to generate implementations at runtime
AI for Test Doubles (Especially Mockito)
AI generates boilerplate; you evaluate whether mocks match reality.
AI assistants are great at generating boilerplate if you keep evaluation in the loop.
Plan first: write the behaviors you need to simulate and verify
Generate: ask AI to produce
when(...)/verify(...)scaffoldingReview: does the mock reflect real dependency behavior?
Break it: introduce a bug — does the test fail?
Argument Matchers: Flexible Matching
Match any value, exact values, or custom predicates.
// Return sample code for ANY repo URL
when(mockGithub.fetchCode(anyString())).thenReturn(sampleCode());
// Verify saveGrade was called with any student ID
verify(mockDatabase).saveGrade(anyString(), anyInt());
// Verify with custom condition
verify(mockNotifier).send(
anyString(),
argThat(message -> message.contains("passed")),
eq(NotificationLevel.INFO)
);
anyString(), any(), eq(), argThat()
Fakes: When You Need Real Behavior
When you need save-then-retrieve, use a working in-memory implementation.
class FakeUserRepository implements UserRepository {
private final Map<String, User> users = new HashMap<>();
@Override
public void save(User user) {
users.put(user.getId(), user);
}
@Override
public User findById(String id) {
return users.get(id);
}
@Override
public List<User> findAll() {
return new ArrayList<>(users.values());
}
}
A working implementation — just simpler than the real database
The Good: Why Test Doubles Work
Speed, determinism, isolation, and easy error simulation.
✓ Speed: Tests run in milliseconds
✓ Determinism: No flaky tests from real APIs
✓ Isolation: Failures point to the code under test
✓ Edge cases: Easy to simulate errors
// Simulating a GitHub API failure — one line!
when(mockGithub.fetchCode(anyString()))
.thenThrow(new GitHubException("API rate limit exceeded"));
The Dangerous: False Confidence
Tests prove code works with your doubles, not with real systems.

The Dangerous: Brittle Tests
Test behavior, not implementation details.
Brittle tests rely on unspecified behaviors:
// BRITTLE: Assumes Set iteration order (unspecified!)
assertThat(recipe.getTags().toString())
.isEqualTo("[vegetarian, quick, healthy]");
// BRITTLE: Exact string match on unspecified message format
verify(mockNotifier).send(eq("email@example.com"),
eq("Your submission passed!"), any());
// BETTER: Test the behavior, not the implementation
assertThat(recipe.getTags()).containsExactlyInAnyOrder(
"vegetarian", "quick", "healthy");
When to Use Test Doubles
If mock setup is more complex than the code, reconsider.
Use test doubles when:
- Dependency is slow or unreliable
- Need to simulate error conditions
- Dependency has side effects (emails, charges)
- Want to verify interactions
Be cautious when:
- Mock setup is more complex than code
- Verifying implementation, not behavior
- Mocking types you don't own
If mock setup is getting elaborate, consider an integration test instead
Connection to Your Assignments
Mutation testing grades whether your tests catch bugs, not just pass.
Your test suites are graded by mutation testing
- We introduce bugs (mutations) into your code
Your tests should catch those bugs
- A test that passes with the bug present = weak test
It's not enough for tests to pass — they must detect bugs!
AI for Test Planning (Plan Mode)
Plan first, generate drafts, then evaluate.
AI assistants are particularly good at generating drafts — especially when you start from a plan.
- Turning “behaviors to test” into test skeletons
- Enumerating edge cases (equivalence classes, boundaries)
Generating Mockito boilerplate (
when/verify)- Creating test data and fixtures
Key rule (L13): only ask AI to produce what you can evaluate.
The Test-First Evaluation Trick
If you can't describe the oracle, you can't evaluate the AI's tests.
Before you ask AI for tests, answer this yourself:
“What would a good test check?”
- What behavior should change for pass vs fail?
What’s the oracle (strong, not “doesn’t crash”)?
- What inputs hit boundaries / equivalence classes?
- What side effects must be verified?
If you can’t answer these, you’re in the “low familiarity” danger zone (L13): you can’t evaluate the output.
Summary
Test scope spectrum: Unit (fast/focused) → Integration → E2E (slow/complete)
Good tests: hermetic, clear, non-brittle, with strong oracles
Test doubles stand in for real dependencies
Stubs return canned answers; spies record interactions; fakes are simplified implementations
Mockito generates test doubles at runtime
Tradeoffs: Speed/isolation vs false confidence/brittleness
Mutation testing: Tests must detect bugs, not just pass (coverage helps find gaps)
AI for testing: plan first, generate drafts, then evaluate (don’t “vibe test”)
Next Steps
Reading: Lecture notes, Mockito documentation (linked on course site)
Next lecture: Designing for Testability