Yesterday's key insight: fire all the requests, don't pay for a thread to wait for each response.
sendCommandAsync(light) — returns immediately, callback fires when the light ACKs
CompletableFuture.allOf(...) — 15 commands in flight, zero idle threads
Platform.runLater() — safely push results back to the GUI thread
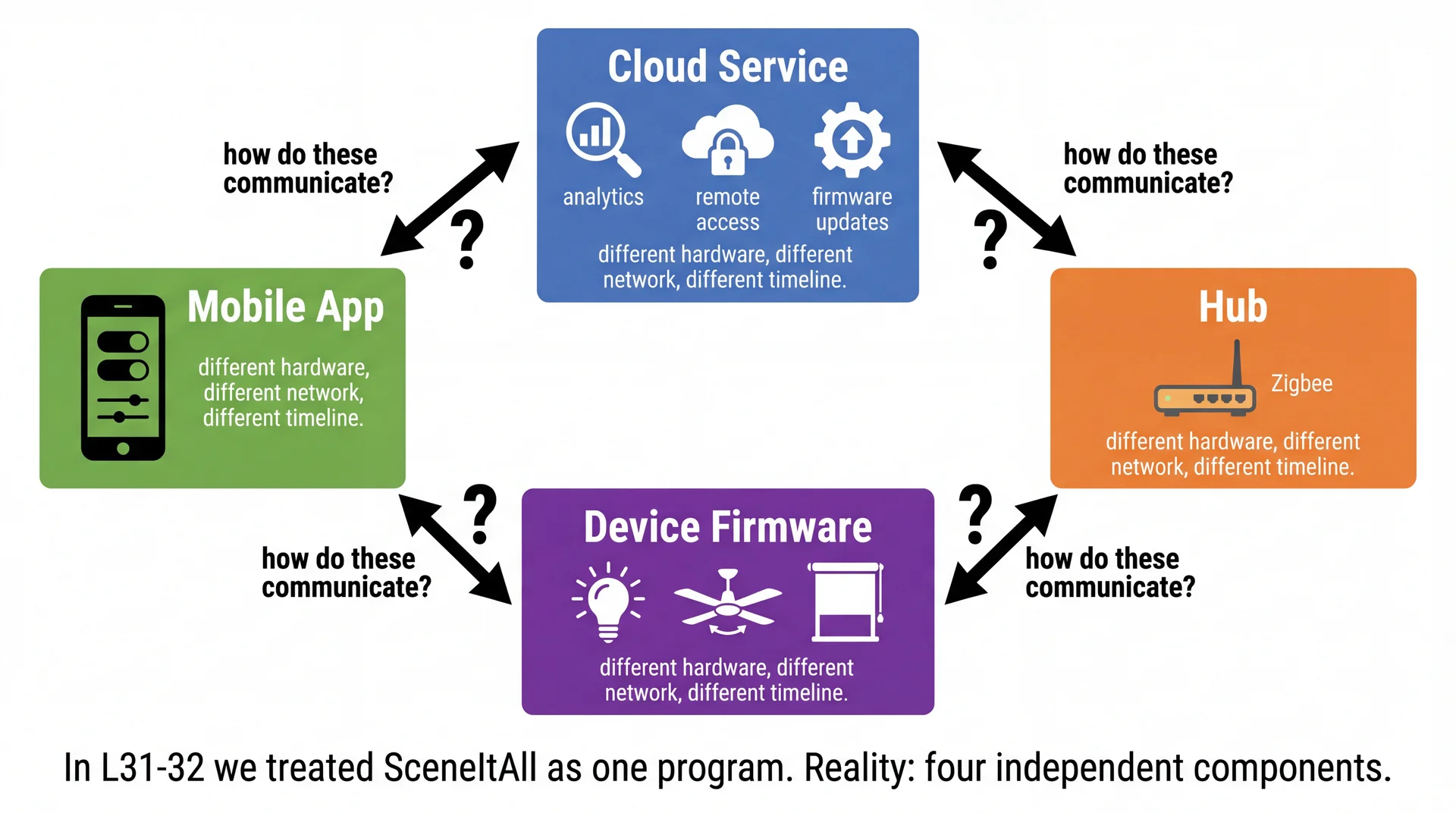
This works beautifully when everything is in one JVM — one hub dispatching commands to devices.
But SceneItAll isn't one JVM. The hub, the mobile app, the cloud service, and device firmware run on different machines, different networks, different timelines. They can't share a thread pool. They can't call each other's methods. When the hub activates a scene, how does the mobile app find out?
The Observer pattern: a subject notifies its observers when state changes. The subject doesn't know who they are.
The pattern in 8 lines:
publicclassSubject<T>{ privatefinalList<Consumer<T>> observers =newArrayList<>(); publicvoidaddObserver(Consumer<T> o){ observers.add(o); } publicvoidsetValue(T val){ for(var o : observers) o.accept(val);// notify all } }
You've used this since L29:
Where
Subject
Observer
L29
Button
onAction handler
L30
IntegerProperty
Bound Slider
L30
ObservableList
Bound ListView
L32
CompletableFuture
thenAccept callback
In every case, the subject doesn't depend on any specific observer. Adding or removing an observer = zero changes to the subject. That's data coupling at most (L7).
Observer works beautifully inside one program. But what happens when the components are on different machines?
// An event is a fact in the past tense publicrecordBrightnessChanged( String eventId, Instant timestamp, String source,// "hub-01" String deviceId, int previousBrightness, int newBrightness ){}
BrightnessChanged, not ChangeBrightness. Events are immutable facts about the past — pinning a note to the bulletin board. The receiver decides how to react.
SceneItAll events:
Event
What happened
DeviceDiscovered
New device on Zigbee network
SceneActivated
User activated a scene
DeviceOffline
Device stopped responding
FirmwareUpdateAvailable
New firmware ready
Each event is immutable and timestamped. No one can change the fact that the brightness changed at 10:32:05 AM.
Without EDA: Adding a Consumer Means Changing the Hub
The hub is coupled to every downstream system. Adding a new consumer means modifying the hub's code.
With EDA: Zero Changes to the Hub When You Add a Consumer
Observer (L29) → Async (L32) → MVVM (L30) → EDA (today) = the same decoupling pattern at increasing scale.
L7: high coupling = a change in one module forces changes in others. Each step reduces what the caller needs to know — from thread lifecycles, to execution timing, to which consumers exist. EDA is information hiding applied to an entire system.
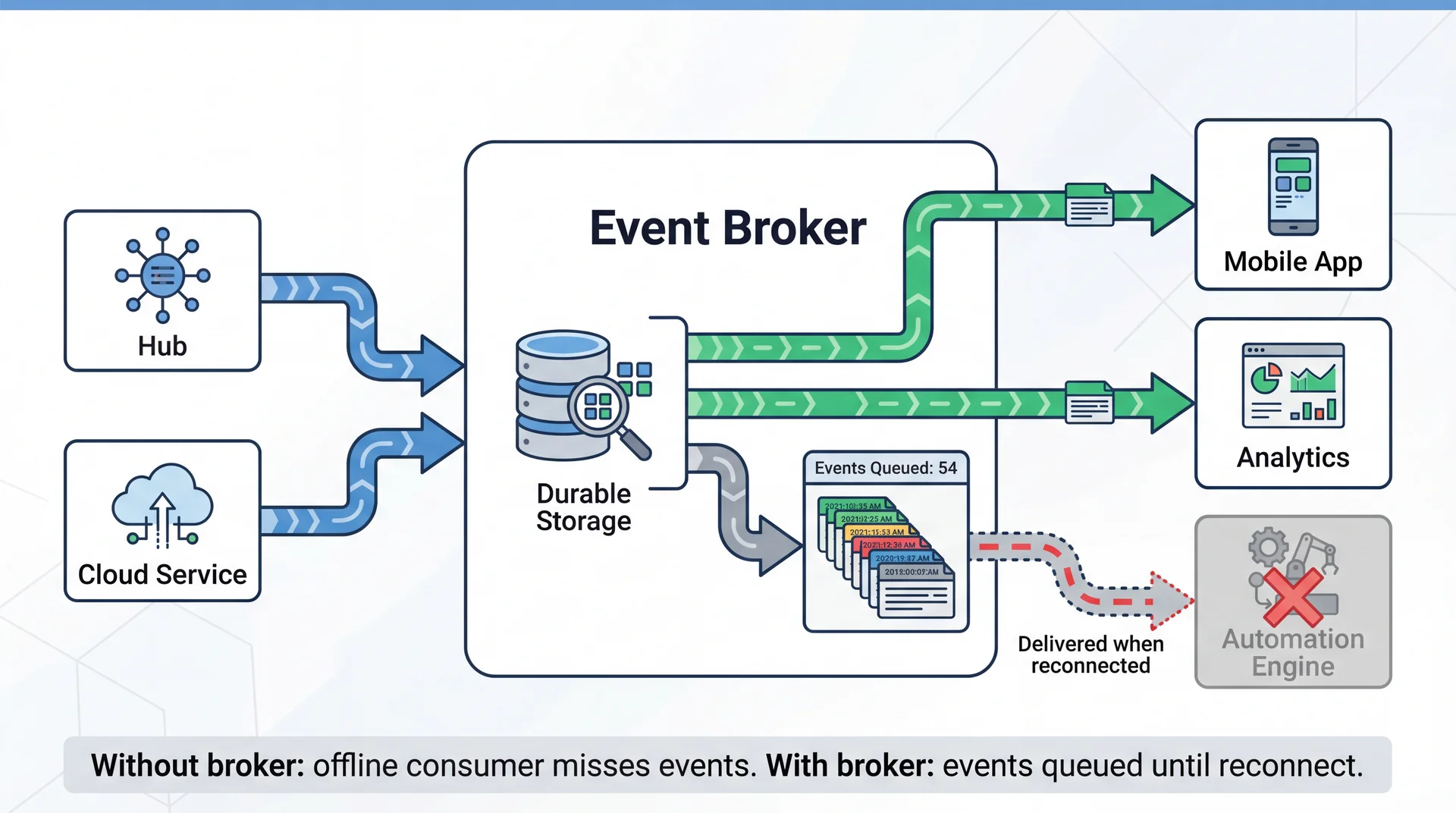
Brokers Store Events So Offline Consumers Don't Miss Them
Events flow through a broker — it stores events durably and delivers them to subscribers. Offline consumer? Events queue until it reconnects. The broker is the bulletin board from our cover image — one place where facts are posted, many people who read and react independently.
Recall L21: message queues decouple submission from processing (Bottlenose grading, Pawtograder repo creation). A broker generalizes that — many producers, many consumers, managed subscriptions. Kafka handles millions of events/sec at Netflix; Zigbee mesh routes events between your hub and a light bulb. L20's resilience patterns — retry with backoff, circuit breakers, rate limiting — compose naturally with brokers and idempotent consumers.
Exactly-Once Is Nearly Impossible — At-Least-Once Is Practical
Guarantee
How it works
Risk
Use case
At-most-once
Fire and forget
Lost events
Analytics pings
At-least-once
Retry until ACK
Duplicate events
Most operations
Exactly-once
Process + ACK atomic
Extremely hard to achieve
Everyone wants this
The practical answer: at-least-once delivery + idempotent consumers.
Accept that duplicates will happen. Design your handlers so processing the same event twice produces the same result as processing it once.
Design Handlers So Processing the Same Event Twice Is Safe
An operation is idempotent if applying it N times has the same effect as applying it once:
Operation
Idempotent?
Why?
light.setBrightness(30)
Yes
Setting to 30 twice = setting to 30 once
light.togglePower()
No
Toggling twice reverts to original state
counter.increment()
No
Incrementing twice adds 2 instead of 1
database.upsert(id, record)
Yes
Upserting same record twice = one record
Design rule: prefer "set to X" over "change by Y." If someone pins the same note to the bulletin board twice, readers who check the note's ID can ignore the duplicate.
// Idempotent handler — safe to process the same event twice voidhandle(BrightnessChanged event){ light.setBrightness(event.newBrightness());// set to X, not change by Y }
Three Screens Show Three Different Answers — Is That a Bug?
You set 30%. Your phone sees it instantly. Roommate's phone sees 100% for 2 seconds. Wall panel sees 100% for 5 seconds. Is the system broken?
Sequential Consistency: One Truth, Everywhere, Always
Sequential consistency means all observers see the same operations in the same order — as if there were one CPU processing everything.
Mental model: a single-threaded program. When you write brightness = 30, every subsequent read returns 30. There's only one copy of the truth.
Like a group text where nobody can send a new message until everyone has read the last one. Simple. Safe. But how do you achieve this across multiple machines?
To make every observer see the same state at the same time, you need coordination:
Wait for the slowest. You set brightness to 30%. The hub can't confirm until your phone, your roommate's phone, AND the wall panel all acknowledge. The wall panel is on a slow Zigbee link — everyone waits.
One failure blocks everyone. Your roommate's phone is in airplane mode. Now nobody can change the brightness until their phone reconnects. The whole system is held hostage by the least reliable participant.
It doesn't scale. 3 consumers = manageable. 50 consumers = every operation waits for 50 acknowledgments. 1000 consumers = unusable.
Sequential consistency is the right choice for safety-critical operations (door locks, alarms) where the cost of disagreement is someone getting hurt. For everything else, there's a cheaper model.
Eventual consistency means: if you stop making changes and wait long enough, all observers will converge to the same state. But at any given moment, they may disagree.
Mental model: a durable message queue. Every event gets delivered to every subscriber — eventually. Some subscribers are faster than others. But no event is lost, and given time, everyone catches up.
Fast: The operation completes as soon as the hub applies it — no waiting for acknowledgments
Resilient: If a consumer is offline, events queue in the broker until it reconnects
Scalable: Adding consumers doesn't slow down the producer
Like posting on social media — you see it, your friend sees it 10 seconds later, everyone converges. The bulletin board model: people wander by and read notes at their own pace.
Use Strong When Someone Could Get Hurt; Eventual for Everything Else
The question: what is the cost of a user seeing stale data for N seconds?
Scenario
Cost of staleness
Model
Door lock state
Someone enters who shouldn't
Sequential
Security alarm
Alarm doesn't trigger
Sequential
Brightness display
Roommate sees old value for 5 sec
Eventual
Scene history log
Last scene shown is 10 sec behind
Eventual
Energy dashboard
Power numbers lag by 30 sec
Eventual
L21 callback: CDN caches and browser caches are eventually consistent — they have been all along. Eventual consistency is the default model of the internet. Sequential consistency is the expensive special case.
Pawtograder uses both consistency models — chosen per use case:
Sequential (via the database)
Grades, submissions, enrollment records. When a TA enters a grade, the database guarantees every subsequent read sees that grade. One source of truth.
Eventual (via event queues)
Outbound: GitHub repo creation, Discord notifications, autograder job dispatch. Inbound: GitHub webhooks (pushes, issues, PR events), Discord interactions (slash commands, reactions). Queues define the boundary in both directions.
This is the architecture from L18-L21 in action: the database is the sequentially consistent core (hexagonal architecture, L16). Event queues are the ports to external systems — outbound to GitHub, Discord, and the autograder; inbound from GitHub webhooks and Discord interactions. Each queue defines an in/out interface (L7: low coupling).
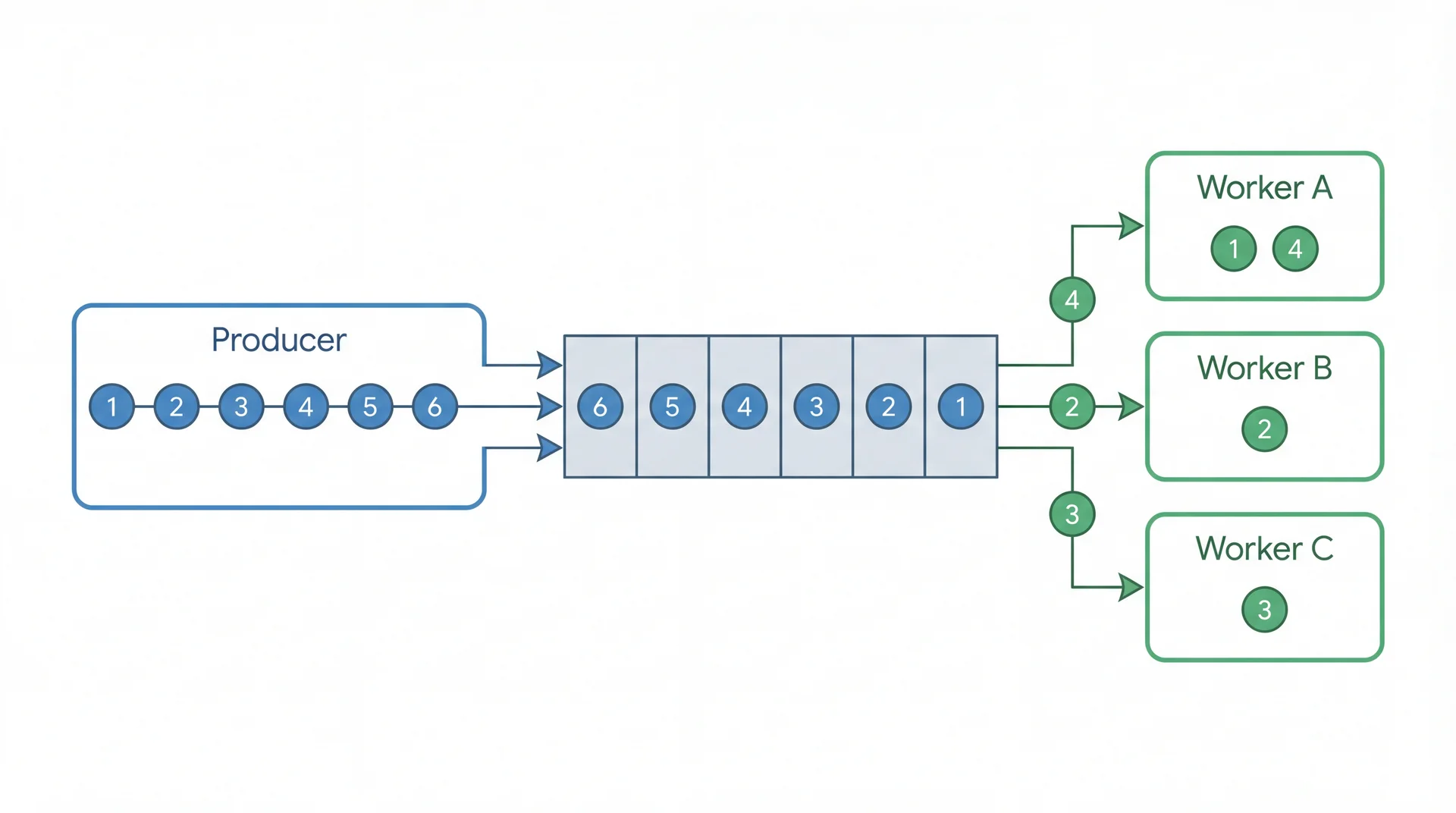
Work Queues: Each Event Goes to Exactly One Worker
Each event goes to exactly one consumer. The broker distributes events among workers.
SceneItAll: 50 device status updates/sec → pool of 5 workers pull from a shared queue. Use for parallelizing work.
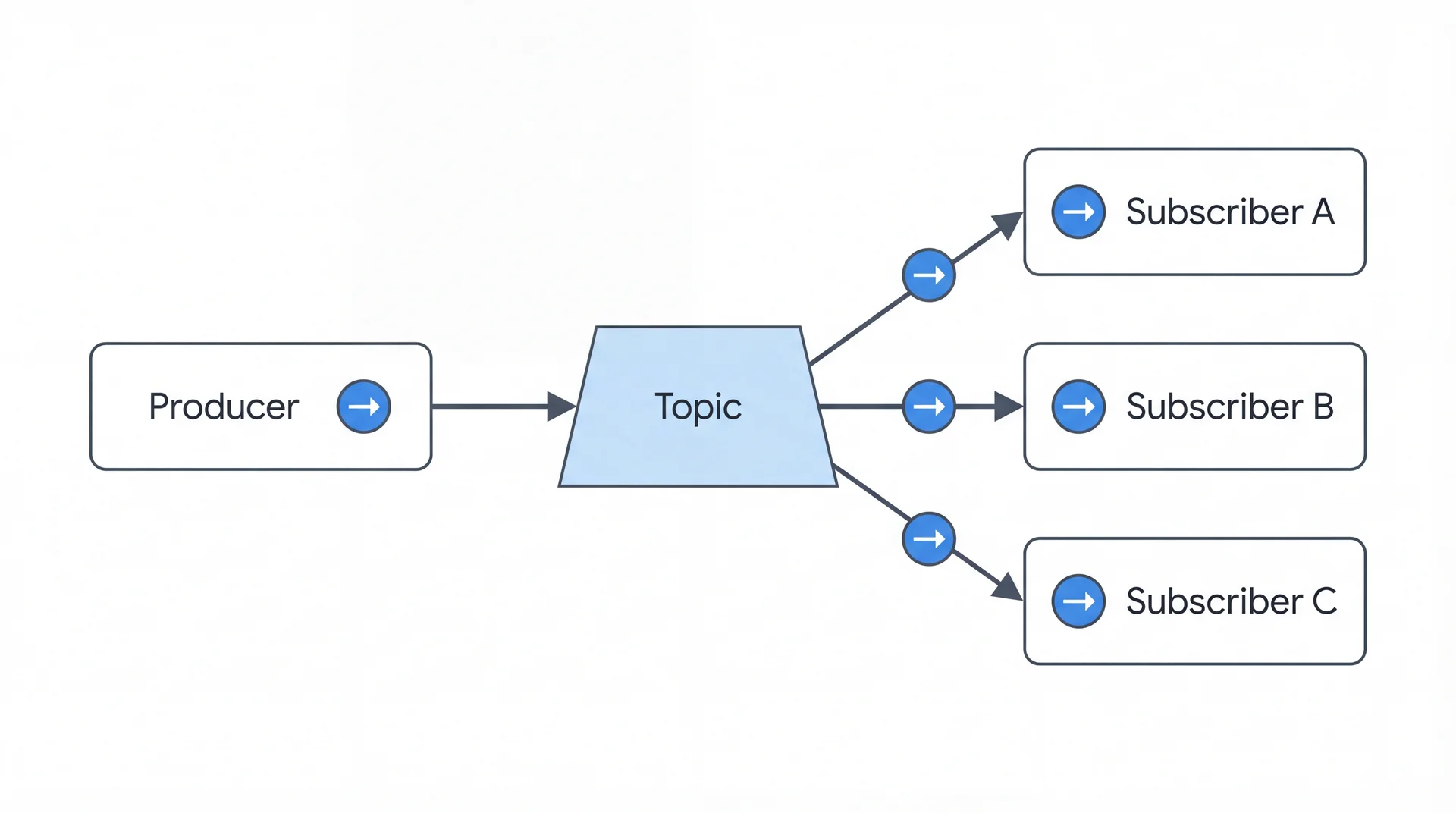
Each event goes to every subscriber. The broker copies the event to each consumer's subscription.
SceneItAll: SceneActivated → mobile app updates UI, analytics logs it, automation checks rules. Use for broadcasting events.
Compare to work queue: there, each event goes to ONE consumer (like a ticket counter). Here, each event goes to EVERY subscriber (like a radio broadcast).
Same Challenge, Increasing Scale: Threads → Async → Events
L31: Threads In-process
→
L32: Async I/O within process
→
L33: EDA Across networks
L31: Threads
L32: Async
L33: EDA
Problem
Shared mutable state
Threads waste resources waiting
Services coupled synchronously
Solution
Locks, concurrent collections
CompletableFuture, allOf
Events, brokers, eventual consistency
Bug category
Race conditions, deadlock
Ordering bugs, swallowed errors
Stale state, cascading failures
Same challenge — managing concurrent operations safely — at increasing scale. This is how every large system works: Netflix, Uber, Slack — and yes, GitHub.
EDA vs Monolith: Quality Attributes Revisited (L18)
Quality Attribute
Monolith
Event-Driven Architecture
Scalability
Scale the whole app, even if only one part is overloaded
Scale individual consumers independently — add workers to the bottleneck
Deployability
Deploy everything at once — one bad change takes down the whole system
Deploy services independently — the broker isolates them
Testability
Must test the whole system together; hard to isolate
Each consumer is independently testable — feed it events, assert on results
Modifiability
Adding a feature may touch many modules
Add a new consumer with zero changes to the publisher (L7)
Availability
One component crash = entire system down
One consumer crash = that consumer's work queues; everything else continues
Debuggability
Stack traces, logs in one place — straightforward
Events scattered across services — need correlation IDs and distributed tracing
EDA wins on most attributes. The trade-off: debuggability. "The lights changed — which service did that?" requires observability tooling that monoliths don't need.
In a microservice or serverless architecture (L21), each service is small and independently deployable. But services fail, restart, and scale independently. Events + brokers provide the reliable interface between unreliable services:
Deployability: Deploy a new version of the analytics service. The broker queues events while it restarts. Zero downtime for the hub or the mobile app.
Fault isolation: The Discord bot crashes. Regrade notifications queue in the broker. When the bot restarts, it processes the backlog. No regrade requests are lost.
Independent scaling: Autograder is overloaded at deadline time. Spin up more workers pulling from the grading queue. The submission service doesn't change.
Debugging: Every event has an ID, a timestamp, and a source. The broker is the audit trail — you can replay events, inspect the DLQ, trace the full lifecycle of a submission.
Events are the contract between services. The broker is the postal service. Each service is free to crash, restart, and evolve — as long as it speaks the same event language.
Your CookYourBooks app uses BackgroundTaskRunner — a utility wrapping javafx.concurrent.Task, daemon threads, and FX-thread callbacks into run(callable, onSuccess, onFailure). You don't write threading boilerplate, but you must understand what it does (your TA will ask).
The error handling patterns from today (idempotency, retry, graceful failure) apply to every async operation in your app.