CS 3100: Program Design and Implementation II
Quiz Review 2

©2026 Ellen Spertus, CC-BY-SA
Poll: How much of the practice quiz did you do?
A. None yet
B. I've skimmed it
C. A few problems
D. Many problems
E. All problems

Poll: How hard do you think it is?

Click below the faces if you haven't tried it yet.
Question 1: Critical Requirements Error
A team discovers a critical requirements error after the system has been deployed to production. According to the cost-of-change model discussed in class, how does the cost of fixing this error compare to catching it during requirements analysis?
- The cost is roughly the same regardless of when it is discovered
- The cost is actually lower in production because the team better understands the system and can make more targeted fixes
- The cost grows exponentially — fixing in production can be 100x more expensive than fixing during requirements
- The cost is approximately 2x higher in production
Catching Problems Late is Expensive
Lecture 1: Systematic Program Design and Implementation Process
- Bug in requirements = cheap to fix
- Bug in production = expensive
Lecture 9: Getting requirements wrong is the most expensive mistake in software engineering.
Lecture 12: Domain Models are Expensive to Change
Lecture 18: Architectural decisions are the ones that are expensive to change.
Lecture 24: Usability
- The best way to know if users can use your software is to watch them use it
- But by the time you have working software, changes are expensive
Poll: What's Not Expensive to Change Late?

Text espertus to 22333 if the
URL isn't working for you.
Question 1 Answer
A team discovers a critical requirements error after the system has been deployed to production. According to the cost-of-change model discussed in class, how does the cost of fixing this error compare to catching it during requirements analysis?
- The cost is roughly the same regardless of when it is discovered
- The cost is actually lower in production because the team better understands the system and can make more targeted fixes
- The cost grows exponentially — fixing in production can be 100x more expensive than fixing during requirements
- The cost is approximately 2x higher in production
Question 2: Stakeholder Conflicts
A product manager, a UX designer, and a backend engineer are all stakeholders for a recipe-sharing feature in CookYourBooks. The product manager wants maximum social engagement, the UX designer wants a simple interface, and the engineer wants to minimize API calls. Which requirements analysis principle does this scenario illustrate?
- Requirements should be gathered only from the person who is paying for the project
- Technical stakeholders should override non-technical stakeholders
- The best approach is to implement all stakeholder requests independently
- Different stakeholders have conflicting values, and requirements analysis must surface and negotiate these conflicts
"It depends"
We can't maximize every metric so need to make trade-offs:
- class design with SOLID principles [Lecture 8]
- requirements analysis [Lecture 9]
- object creation patterns [Lecture 17]
- architectural qualities [Lectures 19, 21]
- usability measures [Lecture 24, not on quiz]
Good, fast, cheap: Choose two


Question 2 Answer
A product manager, a UX designer, and a backend engineer are all stakeholders for a recipe-sharing feature in CookYourBooks. The product manager wants maximum social engagement, the UX designer wants a simple interface, and the engineer wants to minimize API calls. Which requirements analysis principle does this scenario illustrate?
- Requirements should be gathered only from the person who is paying for the project
- Technical stakeholders should override non-technical stakeholders
- The best approach is to implement all stakeholder requests independently
- Different stakeholders have conflicting values, and requirements analysis must surface and negotiate these conflicts
Question 3: Responsibility Assignment Pattern
In the Pawtograder domain model, the RegradeRequest class has a method canEscalate() that checks whether the request has responses, whether it is already resolved, and whether 24 hours have passed since the last response. This is an example of which responsibility assignment pattern?
- Information Expert — RegradeRequest has the data needed to answer the question
- Creator — RegradeRequest creates the escalation
- Singleton — there can only be one active regrade request
- Controller — RegradeRequest handles external system events and coordinates responses across the application
Responsibility Assignment Determines Code Structure
Now we translate our validated domain model into working code.
The critical question: Which classes own which behaviors?
We'll use three key heuristics:
- Information Expert — Who has the data needed?
- Creator — Who should create new objects?
- Controller — Who coordinates complex operations?
Assign Behavior to the Class That Has the Data
Assign responsibility to the class that has the information needed to fulfill it.
Example: Who should determine if a regrade can be escalated?
❌ Ignoring the heuristic:
// Service must extract all data from request
class RegradeService {
boolean canEscalate(RegradeRequest req) {
List<RegradeResponse> responses =
req.getResponses(); // extract
RegradeStatus status =
req.getStatus(); // extract
if (responses.isEmpty()) return false;
if (status == RESOLVED) return false;
// ... more extraction and logic
}
}
Service becomes a "logic hog" that pulls data from passive objects.
✓ Following the heuristic:
// RegradeRequest knows its own history
class RegradeRequest {
private List<RegradeResponse> responses;
private RegradeStatus status;
boolean canEscalate() {
if (responses.isEmpty()) return false;
if (status == RESOLVED) return false;
// Data is RIGHT HERE—no extraction
return coolingOffPeriodPassed();
}
}
Data and behavior stay together. Self-contained.
The Class That Knows Its Constraints Should Enforce Them
Who should check if a grader can review a regrade?
❌ Logic scattered in service:
class RegradeService {
boolean canGraderReview(Grader g, RegradeRequest r) {
// Pull data from grader
GraderType type = g.getType();
int activeCount = g.getActiveGradingCount();
int max = g.getMaxConcurrentGradings();
// Pull data from request
Grader original = r.getOriginalSession()
.getGrader();
// Service implements the logic
if (original.equals(g)) return false;
if (activeCount >= max) return false;
return true;
}
}
Service knows too much about Grader's internals.
✓ Grader is the expert on itself:
class Grader {
private GraderType type;
private int activeGradingCount;
boolean canReviewRegrade(RegradeRequest req) {
// Can't review own work
if (req.getOriginalSession()
.getGrader().equals(this)) {
return false;
}
// Check MY workload (I know it!)
if (activeGradingCount >= getMax()) {
return false;
}
return true;
}
}
Grader knows its own constraints. Easy to test.
Containers Should Create What They Contain
Example: Who should create InlineComment objects?
Key point: This means where should the createComment() method live, not where it should be called from.
❌ Ignoring the heuristic:
// External service creates comments
class CommentService {
InlineComment createComment(
GradingSession session,
SourceFile file, int line, String text) {
InlineComment c = new InlineComment(
session, file, line, text, now());
session.getComments().add(c); // Reaches in!
return c;
}
}
Service reaches into GradingSession's internals. Session loses control of its own state.
✓ Following the heuristic:
// Container creates what it contains
class GradingSession {
private List<InlineComment> comments = ...;
InlineComment addComment(
SourceFile file, int line, String text) {
if (!isActive()) throw new ...;
InlineComment c = new InlineComment(
this, file, line, text, now());
comments.add(c);
return c;
}
}
GradingSession controls its own contents. Can enforce invariants (must be active).
Question 3 Answer
In the Pawtograder domain model, the RegradeRequest class has a method canEscalate() that checks whether the request has responses, whether it is already resolved, and whether 24 hours have passed since the last response. This is an example of which responsibility assignment pattern?
- Information Expert — RegradeRequest has the data needed to answer the question
- Creator — RegradeRequest creates the escalation
- Singleton — there can only be one active regrade request
- Controller — RegradeRequest handles external system events and coordinates responses across the application
Question 4: Domain Modeling
// Version A: Technical-focused
public class SubmissionManager {
private Map<String, List<byte[]>> fileStorage = new HashMap<>();
private Map<String, Integer> versionCounters = new HashMap<>();
private Map<String, Map<String, Object>> gradeData = new HashMap<>();
}
// Version B: Domain-aligned
public class Submission {
private final Student student;
private final Assignment assignment;
private final List<SourceFile> files;
private GradingSession activeGradingSession;
}
What is the primary advantage of Version B over Version A?
-
Version B uses less memory because it has fewer fields
-
Version B has a smaller representational gap — its structure mirrors how stakeholders think about the domain
-
Version B compiles faster because it avoids generic types
-
Version B is required by the Java language specification for domain objects, which mandates named types over raw collections in business logic
🤯 You can use quizmanship to answer the question without reading the code!
Poll: What is this class about?
A. Slightly reducing memory usage
B. Creating understandable programs
C. Making compilation faster
D. Java syntax
Text espertus to 22333 if the
URL isn't working for you.
Question 4 Answer
What is the primary advantage of Version B over Version A?
- Version B uses less memory because it has fewer fields
- Version B has a smaller representational gap — its structure mirrors how stakeholders think about the domain
- Version B compiles faster because it avoids generic types
- Version B is required by the Java language specification for domain objects, which mandates named types over raw collections in business logic
Question 4 Rewrite
Which version of the code has a smaller representational gap, with structure mirroring how stakeholders think about the domain?
// Version A: Technical-focused
public class SubmissionManager {
private Map<String, List<byte[]>> fileStorage = new HashMap<>();
private Map<String, Integer> versionCounters = new HashMap<>();
private Map<String, Map<String, Object>> gradeData = new HashMap<>();
}
// Version B: Domain-aligned
public class Submission {
private final Student student;
private final Assignment assignment;
private final List<SourceFile> files;
private GradingSession activeGradingSession;
}
The structure of the domain-aligned version (B) mirrors how stakeholders think about the domain.
Question 5: AI Collaboration
A developer uses an AI programming agent to generate a complete authentication module without reviewing the generated code or understanding how it works. According to the course's framework for AI collaboration, this is an example of:
- Effective use of AI to maximize productivity
- Pair programming with an AI partner
- The "vibe coding" trap — accepting AI output without applying domain knowledge to evaluate it
- The recommended approach for boilerplate code
The Fundamental Principle: Task Familiarity
Fallacy 4: "The Network Is Secure"
Data crossing networks can be intercepted, modified, or spoofed. Every network boundary is a potential attack surface.
Pawtograder: Without the OIDC token, anyone could POST fake grades. Without HTTPS, a network observer could read or modify grades in transit.
(We'll dive deep on security later in this lecture.)
A Well-Maintained Library Beats DIY for Security
Is it safer to use a popular library or write your own? Almost always use the library — if it's well-maintained.
Why well-maintained libraries win:
- Battle-tested by thousands of users
- Security researchers scrutinize popular projects
- Vulnerabilities get reported and patched
- You benefit from specialists' expertise
When dependencies introduce risk:
- Every dependency is an attack surface
- Transitive dependencies multiply the risk
- Unmaintained dependencies don't get patches
- You're trusting code you've never read
Question 5 Answer
A developer uses an AI programming agent to generate a complete authentication module without reviewing the generated code or understanding how it works. According to the course's framework for AI collaboration, this is an example of:
- Effective use of AI to maximize productivity
- Pair programming with an AI partner
- The "vibe coding" trap — accepting AI output without applying domain knowledge to evaluate it
- The recommended approach for boilerplate code
Question 6: Debugging Approach
When debugging, a developer notices that a Recipe object has an unexpected null value for its instructions field. They form the hypothesis: "The instructions field is set to null in the constructor." They then set a breakpoint in the constructor and run the program. This approach is an example of:
- Rubber duck debugging
- Trial-and-error debugging
- Print-statement debugging
- The scientific method applied to debugging — observe, hypothesize, predict, test
Rubber-Duck Debugging

Ad Hoc Techniques
- Trial-and-error debugging
- Print-statement debugging

The Scientific Method Applied to Debugging
- Observe: Notice unexpected behavior or test failure
- Hypothesize: Form a theory about the cause
- Predict: What evidence would support or refute this?
- Test: Gather evidence (debugger, logging, tests)
- Analyze: Does the evidence support the hypothesis?
- Iterate: Refine hypothesis or implement fix
Question 6 Answer
When debugging, a developer notices that a Recipe object has an unexpected null value for its instructions field. They form the hypothesis: "The instructions field is set to null in the constructor." They then set a breakpoint in the constructor and run the program. This approach is an example of:
- Rubber duck debugging
- Trial-and-error debugging
- Print-statement debugging
- The scientific method applied to debugging — observe, hypothesize, predict, test
Question 7: Test Doubles
Consider this test for a ThermostatController:
@Test
public void activatesHeatingWhenBelowTarget() {
TemperatureSensor mockSensor = mock(TemperatureSensor.class);
HVACService mockHVAC = mock(HVACService.class);
NotificationService mockNotifier = mock(NotificationService.class);
when(mockSensor.readTemperature("livingRoom")).thenReturn(65.0);
ThermostatController controller = new ThermostatController(
mockSensor, mockHVAC, mockNotifier);
controller.adjustToTargetTemperature(72.0, "livingRoom");
verify(mockHVAC).setMode(HVACMode.HEATING, "livingRoom");
verify(mockHVAC).activate("livingRoom");
}
In this test, mockSensor is acting as a (A) stub, (B) mock, (C) integration test fixture, or (D) spy.
Test Doubles: Stand-Ins for Real Dependencies
Stubs return canned answers; fakes work simply; spies record calls.
Stubs
Return canned answers
Fakes
Simplified implementations
Spies
Record what happened
From simplest to most sophisticated
What about mocks? We'll get there.
Stubs: Return Canned Answers
Ignore details you don't care about; return what you need.
class StubGitHubService implements GitHubService {
private final CodeSnapshot fixedCode;
public StubGitHubService(CodeSnapshot code) {
this.fixedCode = code;
}
@Override
public CodeSnapshot fetchCode(String repoUrl) {
return fixedCode; // Always returns the same code
}
}
Ignores the repo URL, always returns sample code — that's fine!
Fakes: When You Need Real Behavior
When you need save-then-retrieve, use a working in-memory implementation.
class FakeUserRepository implements UserRepository {
private final Map<String, User> users = new HashMap<>();
@Override
public void save(User user) {
users.put(user.getId(), user);
}
@Override
public User findById(String id) {
return users.get(id);
}
@Override
public List<User> findAll() {
return new ArrayList<>(users.values());
}
}
A working implementation — just simpler than the real database
Spies: Record What Happened (Decorator Pattern)
Wrap, record, delegate—verify interactions after the fact.
class SpyDatabase implements Database {
private final Database delegate; // Wraps a real implementation
private boolean saveGradeCalled = false;
private String savedStudentId = null;
public SpyDatabase(Database realDatabase) {
this.delegate = realDatabase; // Decorator pattern!
}
@Override
public void saveGrade(String studentId, int score) {
this.saveGradeCalled = true; // Record the call
this.savedStudentId = studentId;
delegate.saveGrade(studentId, score); // Delegate to real impl
}
// Query methods for tests
public boolean wasSaveGradeCalled() { return saveGradeCalled; }
public String getSavedStudentId() { return savedStudentId; }
}
Where Do Mocks Fit In?
These describe the behavior of the test double:
- stub: returns canned answer
- fake: simplified implementation
- spy: records how methods were called
Test doubles can be created
- as ordinary classes (as shown on previous slides)
- at run-time by a mocking framework, such as Mockito
Mockito: Create, Configure, Verify
mock(), when().thenReturn(), verify()—the three operations you'll use most.
mock(Class.class) | Create a test double |
when(...).thenReturn(...) | Configure stub behavior |
verify(mock).method(...) | Check spy recordings |
when(...).thenThrow(...) | Simulate exceptions |
Mockito uses reflection to generate implementations at runtime
Question 7 Answer
@Test
public void activatesHeatingWhenBelowTarget() {
TemperatureSensor mockSensor = mock(TemperatureSensor.class);
HVACService mockHVAC = mock(HVACService.class);
NotificationService mockNotifier = mock(NotificationService.class);
when(mockSensor.readTemperature("livingRoom")).thenReturn(65.0);
ThermostatController controller = new ThermostatController(
mockSensor, mockHVAC, mockNotifier);
controller.adjustToTargetTemperature(72.0, "livingRoom");
verify(mockHVAC).setMode(HVACMode.HEATING, "livingRoom");
verify(mockHVAC).activate("livingRoom");
}
In this test, mockSensor is acting as a:
(A) stub — it returns a pre-configured value without real behavior
(B) Mock object verified with verify() — its primary role here is to assert method calls
(C) Integration test fixture — it connects to real hardware
(D) spy — it records method calls for later verification
Question 8: Test Double Tradeoffs
What is the primary risk of relying exclusively on test doubles (mocks and stubs) for all testing?
- Test doubles are slower than real implementations
- Test doubles violate the Open/Closed Principle
- Test doubles are not supported by modern testing frameworks, which require real object instances to correctly measure code coverage
- Test doubles can give false confidence — tests pass even when real components don't integrate correctly
Choices
Test doubles are slower than real implementations?
- They're often faster, but we don't care about little speed improvements.
Test doubles violate the Open/Closed Principle?
- They have nothing to do with classes being open for extension and closed for modification.
Test doubles are not supported by modern testing frameworks, which require real object instances to correctly measure code coverage?
- Test doubles are real objects (just not production objects). Test frameworks support measuring code coverage but don't require it.
Test doubles can give false confidence — tests pass even when real components don't integrate correctly?
🎯
How Could a Test Double Give False Confidence?
@Test
public void thrusterFiresForCorrectDuration() {
// Create a double of Lockheed Martin's thruster.
ThrusterController mockThruster = mock(ThrusterController.class);
// Verify that the NavigationSystem calls the thruster's
// fire method with 4.45 Newtons.
NavigationSystem nav = new NavigationSystem(mockThruster);
nav.fireThruster(4.45);
verify(mockThruster).fire(4.45);
}
The test passes but the Mars Climate Orbiter fails. Why?
The Mars Climate Orbiter Disaster

Question 8 Answer
What is the primary risk of relying exclusively on test doubles (mocks and stubs) for all testing?
- Test doubles are slower than real implementations
- Test doubles violate the Open/Closed Principle
- Test doubles are not supported by modern testing frameworks, which require real object instances to correctly measure code coverage
- Test doubles can give false confidence — tests pass even when real components don't integrate correctly
Question 9: Hexagonal Architecture
// code omitted
In an IoT EnergyOptimizer, EnergyPricePort is a port and GridPriceApiAdapter (which calls a real pricing API) is an adapter. In Hexagonal Architecture, what is the main benefit of this separation?
- Adapters are faster than direct method calls
- The application core can be tested and reused without depending on any specific external system
- Ports automatically generate REST API endpoints
- The Java compiler requires interfaces for external dependencies involving I/O
Hexagonal Architecture (Ports and Adapters)
The solution is called Hexagonal Architecture, proposed by Alistair Cockburn (2005)
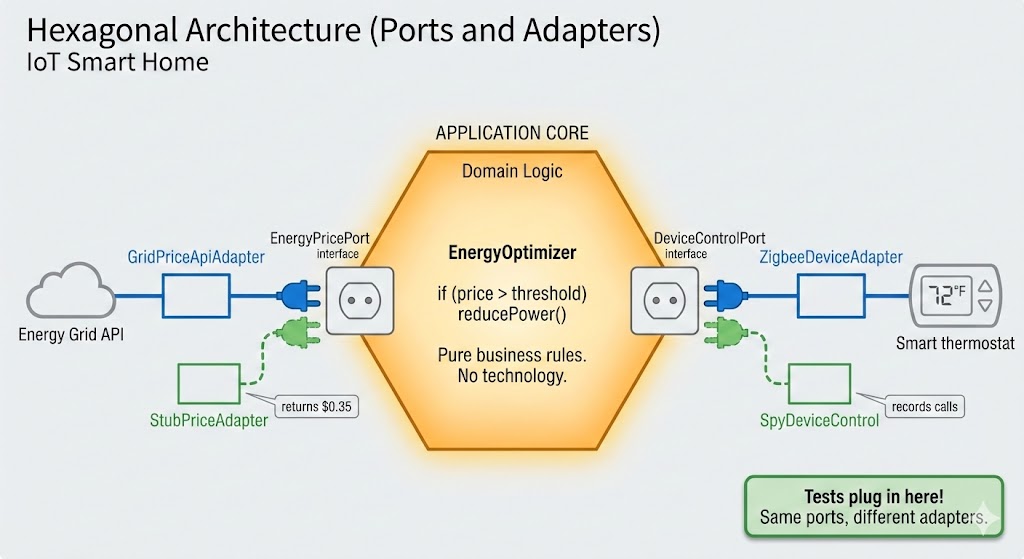
The Three Layers
Core: Knows nothing about databases, APIs, or hardware—only the domain.
Ports: Interfaces that describe what the domain needs, not how to get it.
Adapters: Implementations of the interfaces to talk to specific technologies
Now let's look at the code
public class EnergyOptimizer {
private final EnergyPricePort priceService;
private final DeviceControlPort deviceControl;
private final UserPreferencesPort preferences;
public EnergyOptimizer(EnergyPricePort priceService, DeviceControlPort deviceControl,
UserPreferencesPort preferences) {
this.priceService = priceService;
this.deviceControl = deviceControl;
this.preferences = preferences;
}
}
Question 9 Answer
In an IoT EnergyOptimizer, EnergyPricePort is a port and GridPriceApiAdapter (which calls a real pricing API) is an adapter. In Hexagonal Architecture, what is the main benefit of this separation?
- Adapters are faster than direct method calls
- The application core can be tested and reused without depending on any specific external system
- Ports automatically generate REST API endpoints
- The Java compiler requires interfaces for external dependencies involving I/O
Question 10: Testability Anti-Patterns
Which of the following is an anti-pattern that makes code difficult to test?
- Accepting dependencies through the constructor
- Defining behavior behind interfaces
- Using new to directly instantiate collaborators inside a method, hiding the dependency
- Separating domain logic from infrastructure code
What's an Anti-Pattern?
- A pattern is a positive example that should be applied where appropriate.
- An anti-pattern is a negative example that should be avoided.
Hardcoding Dependencies vs. Dependency Injection
// Hard-coded dependency
public class ImportService {
public ImportService() {
}
public void importRecipe(Path file) {
Recipe recipe = parseRecipe(file);
new LibraryServiceImpl().addRecipe(recipe);
}
}
✗ Using new to directly instantiate collaborators inside a method, hiding the dependency
// Dependency injection
public class ImportService {
private final LibraryService libraryService;
public ImportService(LibraryService libraryService) {
this.libraryService = libraryService;
}
public void importRecipe(Path file) {
Recipe recipe = parseRecipe(file);
libraryService.addRecipe(recipe);
}
}
✓ Accepting dependencies through the constructor
Question 10 Answer
Which of the following is an anti-pattern that makes code difficult to test?
- Accepting dependencies through the constructor
- Defining behavior behind interfaces
- Using new to directly instantiate collaborators inside a method, hiding the dependency
- Separating domain logic from infrastructure code
Question 11: Hidden Dependencies
// code omitted
In an ImportService, the method importRecipe() calls LibraryService.getInstance().addRecipe(recipe). What problem does the LibraryService.getInstance() call introduce?
- It makes ImportService slower by calling a static method
- It causes a NullPointerException at runtime
- It creates a hidden dependency that cannot be replaced for testing or reuse
- It violates the Single Responsibility Principle because ImportService now manages library instances
Consider the Code
public class ImportService {
public void importRecipe(Path file) {
Recipe recipe = parseRecipe(file);
LibraryService.getInstance().addRecipe(recipe);
}
}
This has exactly the same problem as in the previous question.
Hardcoding dependencies vs. dependency injection
// Hard-coded dependency
public class ImportService {
public ImportService() {
}
public void importRecipe(Path file) {
Recipe recipe = parseRecipe(file);
// two bad options, hardcoding dependencies
new LibraryServiceImpl().addRecipe(recipe);
LibraryService.getInstance().addRecipe(recipe);
}
}
✗ Hardcoding dependency with new
✗ Hardcoding dependency with static method call
// Dependency injection
public class ImportService {
private final LibraryService libraryService;
public ImportService(LibraryService libraryService) {
this.libraryService = libraryService;
}
public void importRecipe(Path file) {
Recipe recipe = parseRecipe(file);
// Use LibraryService injected through constructor
libraryService.addRecipe(recipe);
}
}
✓ Accepting dependencies through the constructor
Question 11 Answer
In an ImportService, the method importRecipe() calls LibraryService.getInstance().addRecipe(recipe). What problem does the LibraryService.getInstance() call introduce?
- It makes ImportService slower by calling a static method
- It causes a NullPointerException at runtime
- It creates a hidden dependency that cannot be replaced for testing or reuse
- It violates the Single Responsibility Principle because ImportService now manages library instances
Question 12: Dependency Injection
A developer refactors ImportService so that LibraryService is passed in through the constructor rather than looked up via getInstance(). This refactoring applies which pattern?
- Strategy Pattern — the algorithm for importing is swappable
- Dependency Injection — the dependency is provided externally rather than looked up internally
- Service Locator — ImportService looks up its dependency from a central registry rather than receiving it from the outside
- Builder Pattern — the ImportService is constructed step by step
Question 12 Answer
A developer refactors ImportService so that LibraryService is passed in through the constructor rather than looked up via getInstance(). This refactoring applies which pattern?
- Strategy Pattern — the algorithm for importing is swappable
- Dependency Injection — the dependency is provided externally rather than looked up internally
- Service Locator — ImportService looks up its dependency from a central registry rather than receiving it from the outside
- Builder Pattern — the ImportService is constructed step by step
Question 13: Architecture Decision Records
What is an Architecture Decision Record (ADR)?
- A log file generated by the build system that records compilation decisions, dependency resolutions, and warnings for later auditing
- A UML diagram showing all classes in the system
- A performance benchmark comparing different architectural approaches
- A short document that captures the context, decision, and consequences of a significant architectural choice
Architecture Decision Records (ADRs)
Diagrams show what. ADRs capture why. An ADR documents: Context, Decision, and Consequences.
ADR-001: Centralized Feed Algorithm vs. Per-Server Algorithm
Context: We need to rank posts for each user's feed. We could rank centrally using global engagement signals, or let each server (or user) choose their own algorithm.
Decision: Chirp will rank feeds centrally using a shared EngagementStrategy. The RankingStrategy interface is retained to allow A/B testing of algorithms internally.
Consequences:
- ✅ Consistency: All users get a coherent, optimized experience
- ✅ Changeability: New algorithms can be tested without touching the Feed Service
- ✅ Scalability: Ranking infrastructure can be optimized centrally
- ⚠️ Autonomy: Users cannot opt out of the platform's ranking choices
- ⚠️ Coupling: Feed quality is tied to the platform's data — if engagement data degrades, all feeds degrade
ADR-001: Patron Service Boundaries
Context: The client used by the Patron needs to be able to make requests of a service layer that applies business logic to repositories. We were constrained to prioritize the Actor service boundary heuristic.
Decision: We will have these separate service interfaces supporting these commands:
HoldServicehold bookholds
[remainder omitted]
We separated HoldService from other services, such as AccountService because of the former's greater rate of change.
Consequences:
- ✅ Decoupling: Changes to hold policy affect only
HoldServiceand its implementations, not other services, such asAccountService. - ⚠️ Testability: We need to mock
BookRepositoryto test the methodisPermittedToPlaceHold(), even though that method does not referenceBookRepository.
Question 13 Answer
What is an Architecture Decision Record (ADR)?
- A log file generated by the build system that records compilation decisions, dependency resolutions, and warnings for later auditing
- A UML diagram showing all classes in the system
- A performance benchmark comparing different architectural approaches
- A short document that captures the context, decision, and consequences of a significant architectural choice
Question 14: Service Boundary Heuristics
When determining where to draw service boundaries in a system, which of the following is a valid heuristic discussed in class?
- Group code that changes together and for the same reasons; separate code that changes independently or for different actors
- Each service should contain exactly one class
- Service boundaries should follow alphabetical ordering of class names
- All database access should be in a single service to minimize connection pooling overhead and ensure a consistent data access layer across the system
Service Boundary Heuristics
-
Actor: Things used by different actors should be separate.
-
Rate of Change: Things that change at different speeds should be separate. [This is about code, not data.]
-
Interface Segregation: Clients that need different things should get different interfaces. [Clients aren't people. They are classes, microservices, and GUIs.]
-
Testability: Things that need independent testing should be separable.
Question 14 Answer
When determining where to draw service boundaries in a system, which of the following is a valid heuristic discussed in class?
- Group code that changes together and for the same reasons; separate code that changes independently or for different actors
- Each service should contain exactly one class
- Service boundaries should follow alphabetical ordering of class names
- All database access should be in a single service to minimize connection pooling overhead and ensure a consistent data access layer across the system
Question 15: How Team Structure Shapes Architecture
A company has three teams: a frontend team, a backend team, and a database team. They build a system with three layers: a presentation layer, an application layer, and a data access layer. According to Conway's Law, why is this architecture unsurprising?
- Three-layer architectures are the best design for web applications because they cleanly separate presentation, business logic, and data concerns
- The company chose the best architecture for performance reasons
- Organizations tend to produce system designs that mirror their own communication structures
- The Java language specification requires layered architectures
Conway's Law: Teams Shape Architecture
“Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations.”
Translation: Your software's architecture will mirror your team's structure—whether you plan for it or not.
Example: Three teams working on one app → three separate services that need integration
Question 15 Answer
A company has three teams: a frontend team, a backend team, and a database team. They build a system with three layers: a presentation layer, an application layer, and a data access layer. According to Conway's Law, why is this architecture unsurprising?
- Three-layer architectures are the best design for web applications because they cleanly separate presentation, business logic, and data concerns
- The company chose the best architecture for performance reasons
- Organizations tend to produce system designs that mirror their own communication structures
- The Java language specification requires layered architectures
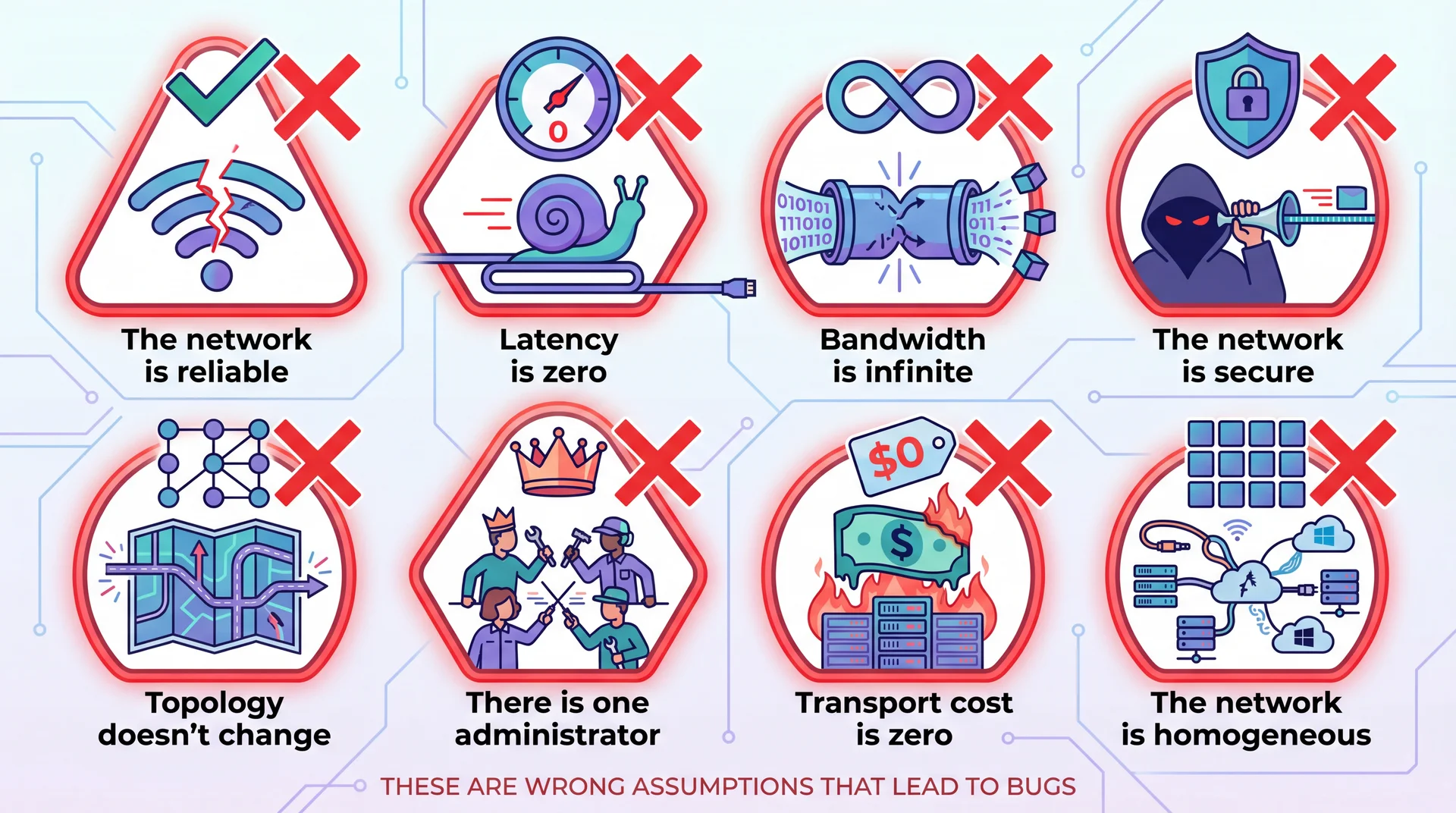
Question 16: Fallacies of Distributed Computing
"The network is reliable" is the first of the Eight Fallacies of Distributed Computing. A developer writes code that calls a remote recipe-sharing API without any error handling. When the network is temporarily unavailable, the application crashes. Which design strategy would address this fallacy?
- Increase the server's RAM to handle more requests, since network failures are often caused by servers running out of memory under load
- Implement timeouts, retries with exponential backoff, and graceful degradation
- Switch from HTTP to a faster protocol
- Cache all data locally and never use the network
The Fallacies of Distributed Computing
Question 16 Answer
"The network is reliable" is the first of the Eight Fallacies of Distributed Computing. A developer writes code that calls a remote recipe-sharing API without any error handling. When the network is temporarily unavailable, the application crashes. Which design strategy would address this fallacy?
- Increase the server's RAM to handle more requests, since network failures are often caused by servers running out of memory under load
- Implement timeouts, retries with exponential backoff, and graceful degradation
- Switch from HTTP to a faster protocol
- Cache all data locally and never use the network
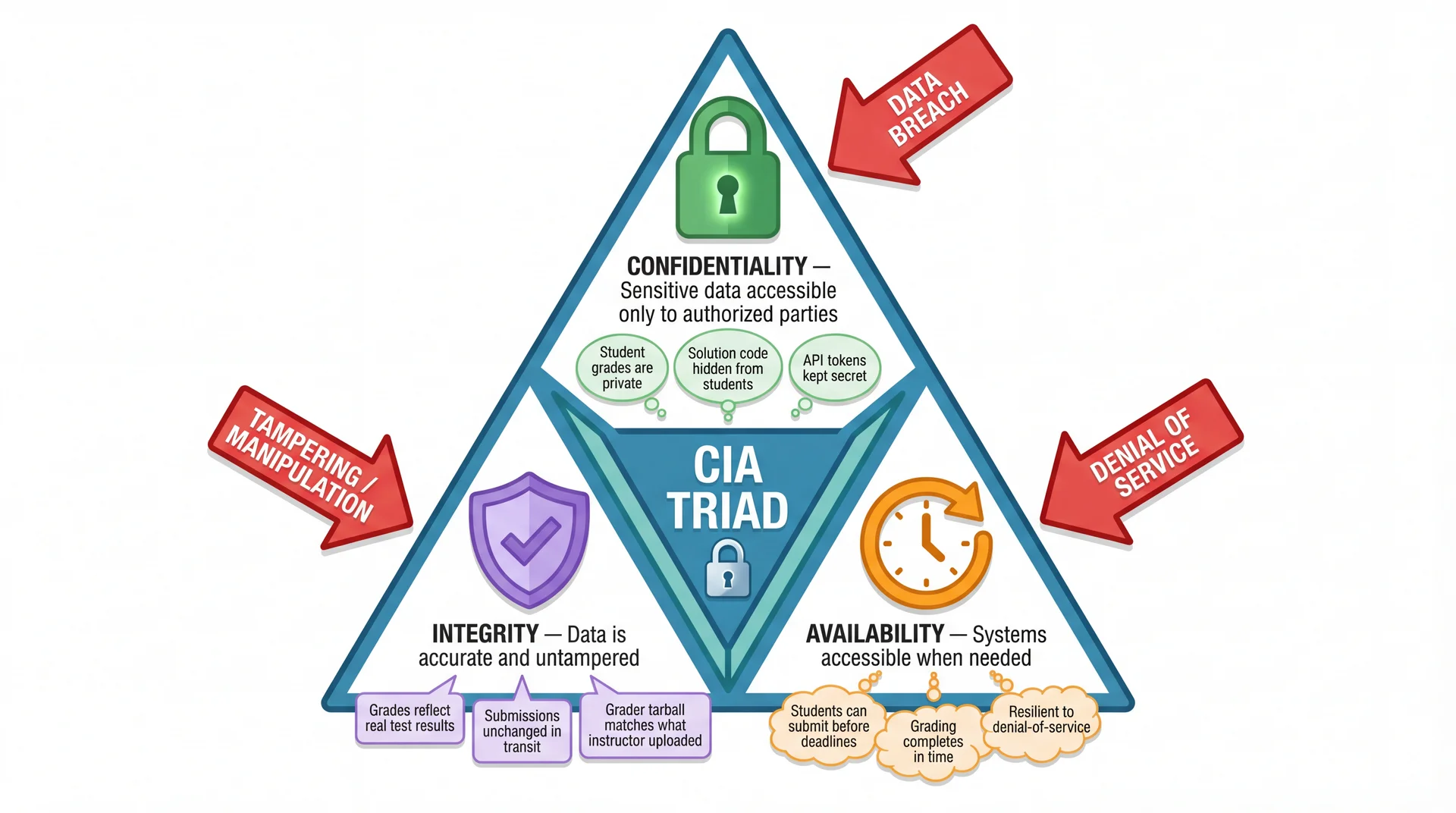
Question 17: CIA Triad
In the CIA Triad for security, what do Confidentiality, Integrity, and Availability mean?
- Confidentiality means data is only accessible to authorized parties; Integrity means data is not tampered with; Availability means the system is accessible when needed
- Confidentiality means fast response times; Integrity means code compiles; Availability means 24/7 customer support
- Confidentiality means using encryption everywhere; Integrity means using checksums; Availability means using load balancers
- These are three types of software testing methodologies
Security Decisions Trade Off Confidentiality, Integrity, and Availability
Question 17 Answer
In the CIA Triad for security, what do Confidentiality, Integrity, and Availability mean?
- Confidentiality means data is only accessible to authorized parties; Integrity means data is not tampered with; Availability means the system is accessible when needed
- Confidentiality means fast response times; Integrity means code compiles; Availability means 24/7 customer support
- Confidentiality means using encryption everywhere; Integrity means using checksums; Availability means using load balancers
- These are three types of software testing methodologies
Question 18: Graceful Degradation
A CookYourBooks developer adds a feature that calls a remote nutrition API. During testing, the API occasionally takes 30 seconds to respond. The developer adds a 5-second timeout and returns cached nutrition data when the API is slow, along with a warning that the data may not be up-to-date. This design applies which distributed systems concept?
- Horizontal scaling — adding more servers to handle the load
- The CIA Triad — ensuring confidentiality of nutrition data
- Conway's Law — the team structure determines the API design
- Graceful degradation — providing reduced but functional service when a dependency is unavailable
Vertical and Horizontal Scaling (Servers)
How does the system handle growth in load, data, or users?
Vertical Scaling
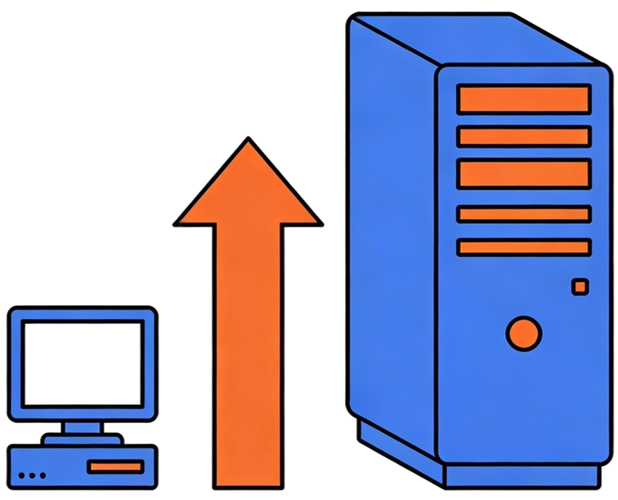
Horizontal Scaling
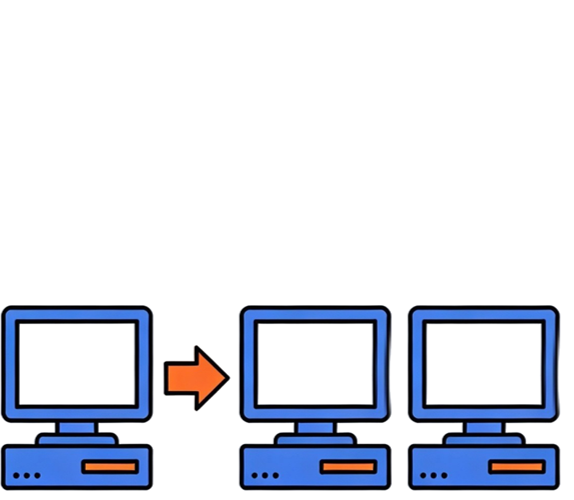
Vertical and Horizontal Scaling (People)

Question 18 Answer
A CookYourBooks developer adds a feature that calls a remote nutrition API. During testing, the API occasionally takes 30 seconds to respond. The developer adds a 5-second timeout and returns cached nutrition data when the API is slow, along with a warning that the data may not be up-to-date. This design applies which distributed systems concept?
- Horizontal scaling — adding more servers to handle the load
- The CIA Triad — ensuring confidentiality of nutrition data
- Conway's Law — the team structure determines the API design
- Graceful degradation — providing reduced but functional service when a dependency is unavailable
Question 19: Brooks' Law
According to Brooks' Law, what happens when you add more developers to a late software project?
- The project gets even later because communication overhead grows quadratically with team size
- The project gets back on schedule because there are more people working
- The project speed is unaffected because individual productivity stays the same and new developers can immediately work on independent tasks
- The project finishes faster but with lower quality code
Brooks' Law
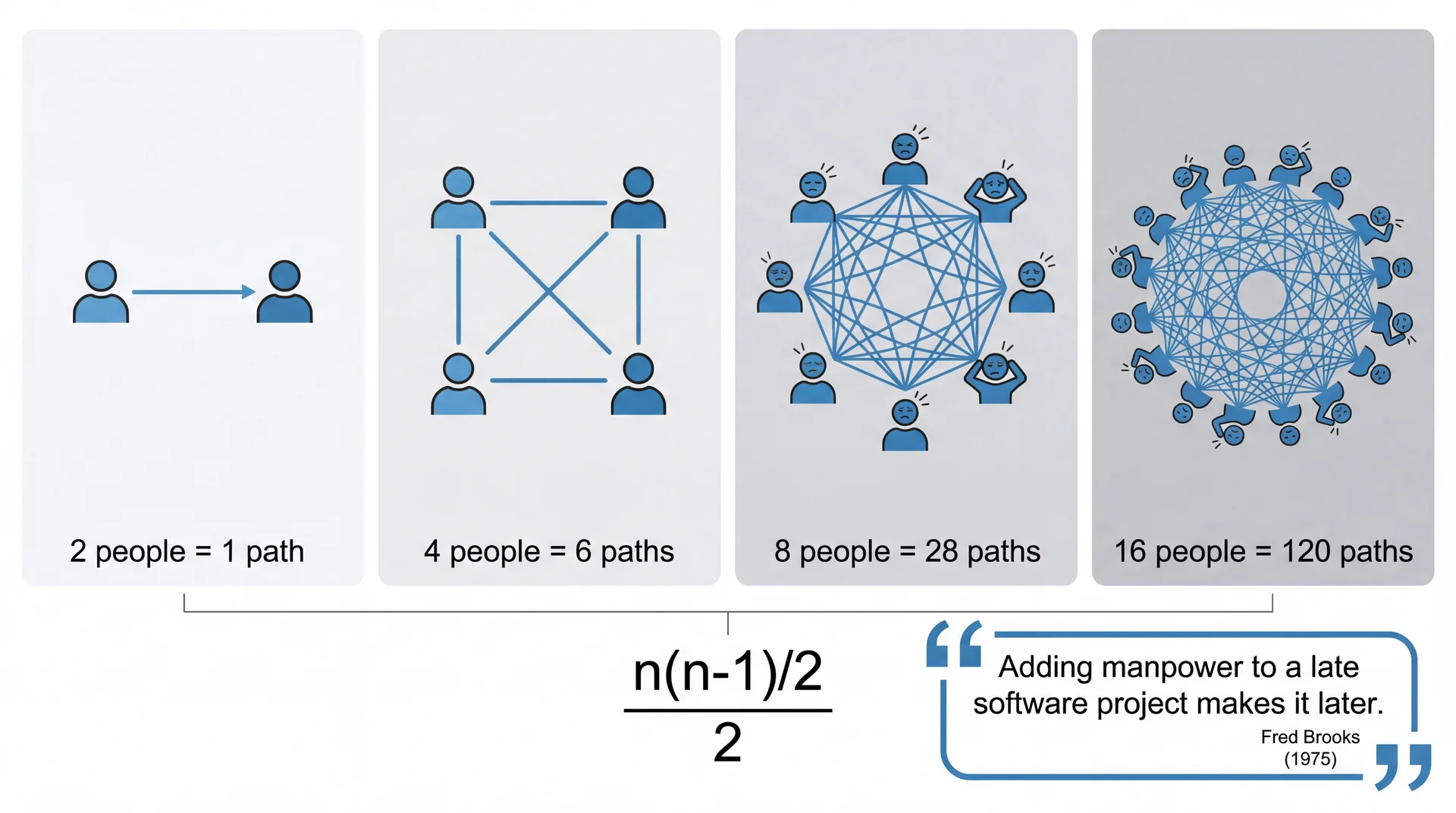
Question 19 Answer
According to Brooks' Law, what happens when you add more developers to a late software project?
- The project gets even later because communication overhead grows quadratically with team size
- The project gets back on schedule because there are more people working
- The project speed is unaffected because individual productivity stays the same and new developers can immediately work on independent tasks
- The project finishes faster but with lower quality code
Question 20: Open Source Licensing
A startup is considering including open-source libraries in their proprietary (closed-source) commercial product. Should the specific licenses of the libraries affect their decision?
- No, they should make the decision purely based on the library quality
- No, all open-source licenses forbid inclusion in commercial code, so they cannot use any of them
- Yes, some open-source libraries require derivative works to also share their source code
- Yes, some open-source licenses provide quality guarantees, which will make their product more reliable
💡Be skeptical of answers that say "all", "always", or "never".
Two Philosophies: Maximize Adoption vs. Protect the Commons

Question 20 Answer
A startup is considering including open-source libraries in their proprietary (closed-source) commercial product. Should the specific licenses of the libraries affect their decision?
- No, they should make the decision purely based on the library quality
- No, all open-source licenses forbid inclusion in commercial code, so they cannot use any of them
- Yes, some open-source libraries require derivative works to also share their source code
- Yes, some open-source licenses provide quality guarantees, which will make their product more reliable
Announcement
ASNUO is hosting a peer-led midterm review session for CS3100 on Monday (March 16) from 8–10 PM in GSB 101. The session is drop-in style, and students from any section are welcome. Snacks and energy drinks(!) will be provided.
Conclusion
Quizmanship
- Remember what we are emphasizing in this class: scalable software, not:
- optimizing performance
- Java details
- Be skeptical of answers with "always", "all", or "never".
Topics
- We've reviewed many important topics from Lecture 9 to Lecture 24.
- There are other important topics I did not review, including (but not limited to)
- Domain Modeling
- Fallacies of Distributed Computing
- REST APIs
- Teams & Collaboration
- I am happy to do so in the remaining time or to go through Prof. Bell's slides.
Bonus Slide
![Frank and Ernest comic strip in which Frank gives Ernest an electricity quiz.
Question 1: 'What do we use to carry electricity?' Ernest answers 'why... err...' [wire] (correct).
Question 2: 'What is the name for a unit of energy?' Ernest answers 'What! [Watt]' (correct).
Question 3: 'Can you tell me the term for when current passes through your body?'
Ernest answers 'Well, that would be a shock!' — which is both the correct answer and his reaction to getting a perfect score.](/CS3100-Spring-2026/img/lectures/web/l25-electricity-quiz.gif)