
CS 3100: Program Design and Implementation II
Lecture 38: MapReduce
©2026 Jonathan Bell & Ellen Spertus, CC-BY-SA
Learning Objectives
After this lecture, you will be able to:
- Give examples of paradigm shifts
- Give examples of programming paradigms
- Describe the MapReduce programming model and GFS at the level needed to analyze their design decisions
Analyze MapReduce and GFS architectural decisions using quality attributes from the course- Identify how MapReduce and GFS apply patterns learned throughout the semester
Evaluate sustainability and trade-off dimensions of MapReduce and GFS- Describe how hasty actions can cause lasting damage
Reminder: We Want Your Feedback
Comments from this Morning
I went through the practice test, and I do not understand why we have short answer questions, as opposed to the other campuses, which do not.
- Most other sections do have short answer questions.
- We believe that is the best way for students to demonstrate their knowledge.
We haven't had short answer response questions on a test for the whole year, and I feel unprepared with this sudden change.
- That's why we created the practice finals.
- Finals are often different for midterms.
- Your assignments and labs should have prepared you.
I feel challenged by having to write code down physically.
- I agree it's not the best way to write code, but needs must.
- We won't grade on syntax.
- This lets us see if students have learned from assignments.
I feel we should have consistency across sections.
- It's fine that you feel that way, but it's not standard in college.
- I believe my questions are easier than Prof. Bell's.
Please don't ask for exceptions from course policies.
Paradigm Shifts
A paradigm is a way of viewing the world.
A paradigm shift is a change of worldview.
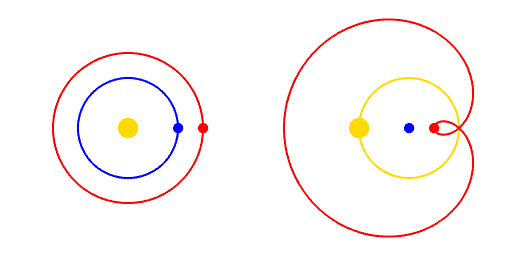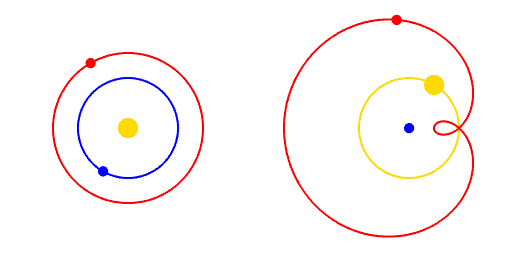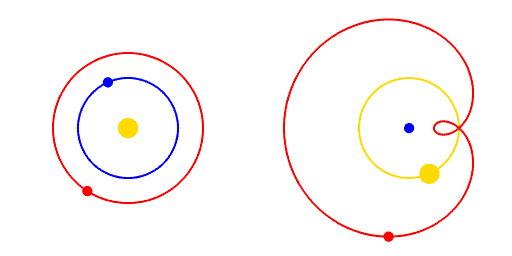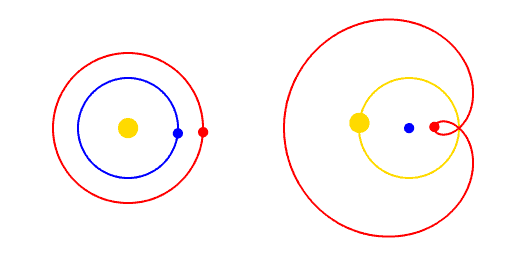
"Apparent retrograde motion" by Cleonis, Wikimedia Commons, CC BY-SA 2.5
{kind=link}
A Paradigm Shift in Information Retrieval (1990s)
Pre-Web Era (Cathedral)
- Curated, centrally-controlled collections
- Thousands of documents with controlled growth
- Content signals trustworthy — no incentive to game them
Web Era (Bazaar)
- Decentralized, chaotic — anyone can publish
- Billions of documents with uncontrolled growth
- Content signals easily gamed (keyword stuffing)
Traditional information retrieval algorithms relied on keywords and metadata to find the best matches in flat text collections.
That didn't work for web search. What did?
PageRank Algorithm
en:User:345Kai, User:Stannered, Public domain, via Wikimedia Commons
{kind=link}
Moore's Law
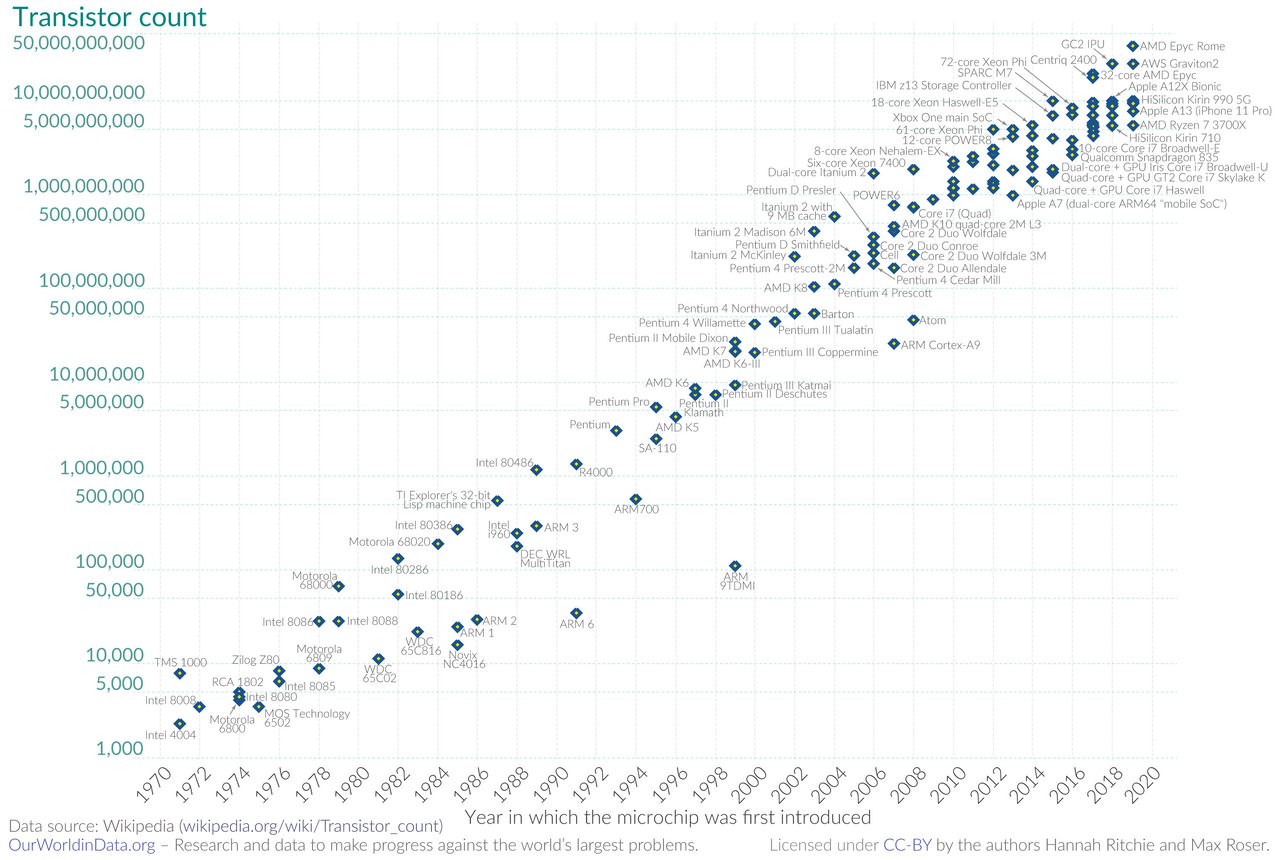
Max Roser, Hannah Ritchie, CC BY 4.0, via Wikimedia Commons
Wirth's Law
“Software gets slower more rapidly than hardware gets faster.”
Niklaus Wirth

Setting the Scene (Early 2000s)
In 2003, Google was crawling billions of web pages.
| Per web page | Total crawl (billions of pages) | |
|---|---|---|
| Raw data | ~100 KB | Hundreds of TB |
| Words to index | ~500 unique | Trillions of index entries |
| Links to follow | ~50 outbound | Hundreds of billions of edges |
Servers had ~2 TB of storage and had ~1/1000th the power of today's computers.
How could they store and process all of that information?
Two Systems, One Case Study
In 2003-2004, Google published two papers that changed how the industry processes data:
Google File System (GFS, 2003)
Stores data across thousands of machines. A NameNode (GFS master) manages metadata (which machines hold which chunks). DataNodes (GFS chunkservers) store the actual data.
Solved the storage problem.
MapReduce (2004)
Distributes computation across thousands of machines. A coordinator assigns tasks and handles failures. Workers execute user-defined functions.
Solved the computation problem.
Today we use these systems as a lens to see every concept from the semester in one place — coupling, cohesion, information hiding, requirements, architecture, concurrency, consistency, performance, safety, and sustainability.
Start with Requirements: What Does This System Need to Do?
From L9 and L18: requirements drive architecture. Before we look at MapReduce and GFS, let's state what the system needs — using the quality scenario format.
| Source | Stimulus | Environment | Response | Measure | |
|---|---|---|---|---|---|
| Throughput | Search infrastructure | Rebuild the web index from billions of crawled pages | Hundreds of TB of raw data, thousands of commodity machines | Produce inverted index, PageRank scores | Complete in hours, not weeks |
| Fault tolerance | Hardware | Machine crashes mid-computation | 1000+ machines; failures are routine, not exceptional | Recover and continue without restarting the job | No data loss; no human intervention |
| Scalability | Web growth | The web is growing exponentially | Same codebase, same programming model | Add machines, not rewrite software | Linear throughput scaling with machines added |
These three requirements — throughput, fault tolerance, scalability — shaped every architectural decision in MapReduce and GFS. As we walk through the system, ask: which requirement drove this decision?
Programming Paradigms
Object-Oriented Programming
Functional Programming
Which is best? It depends.
Have both in your toolkit.
The Map and Reduce Higher-Order Functions
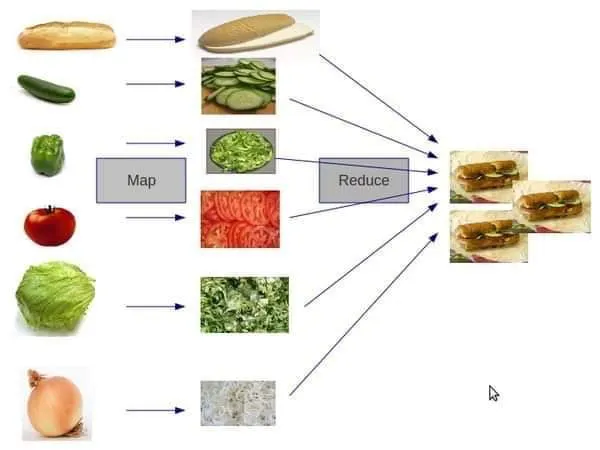
map applies a function to every element in a list
reduce combines a list into a single item
Counting Words on the Web with MapReduce
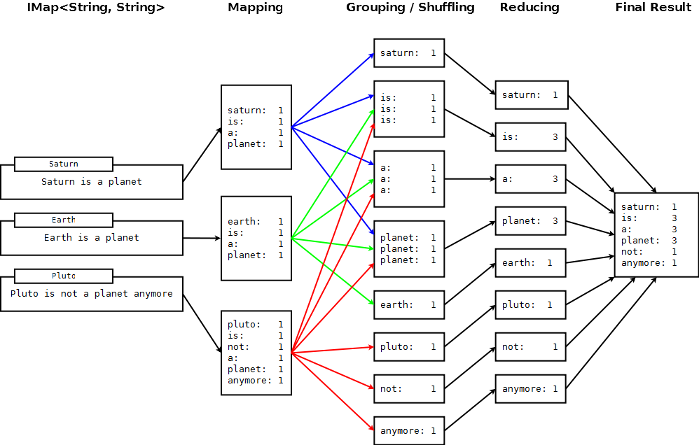
map(key:String, document:String):Void ->
for each w:word in document:
emit(w, 1)
reduce(word:String, counts:List[Int]):Int ->
return sum(counts)
Sandwich MapReduce with Shuffle
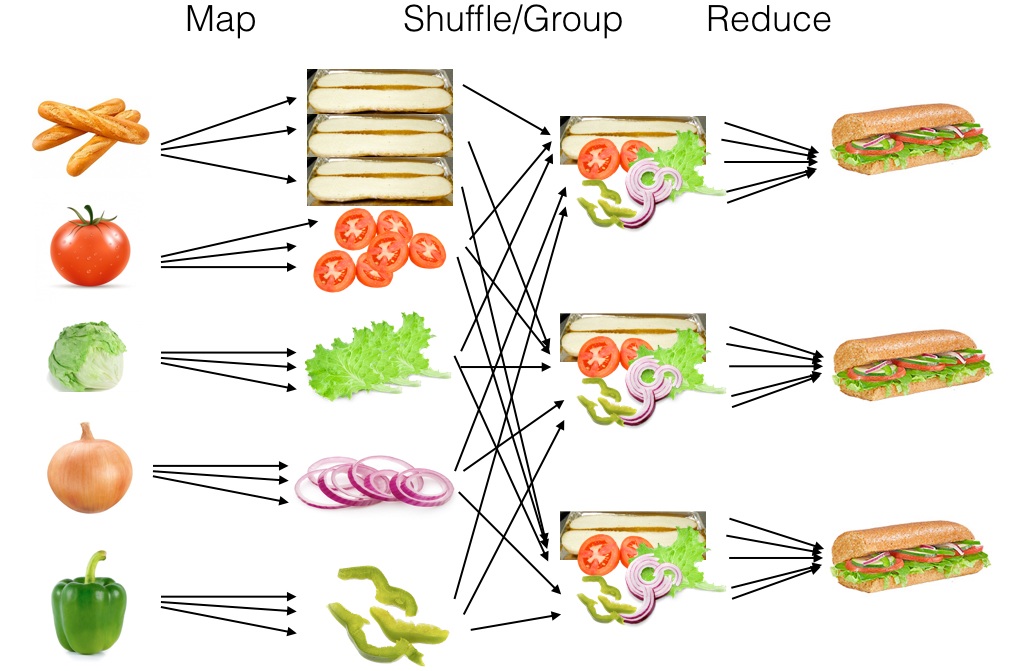
Building an Index with MapReduce
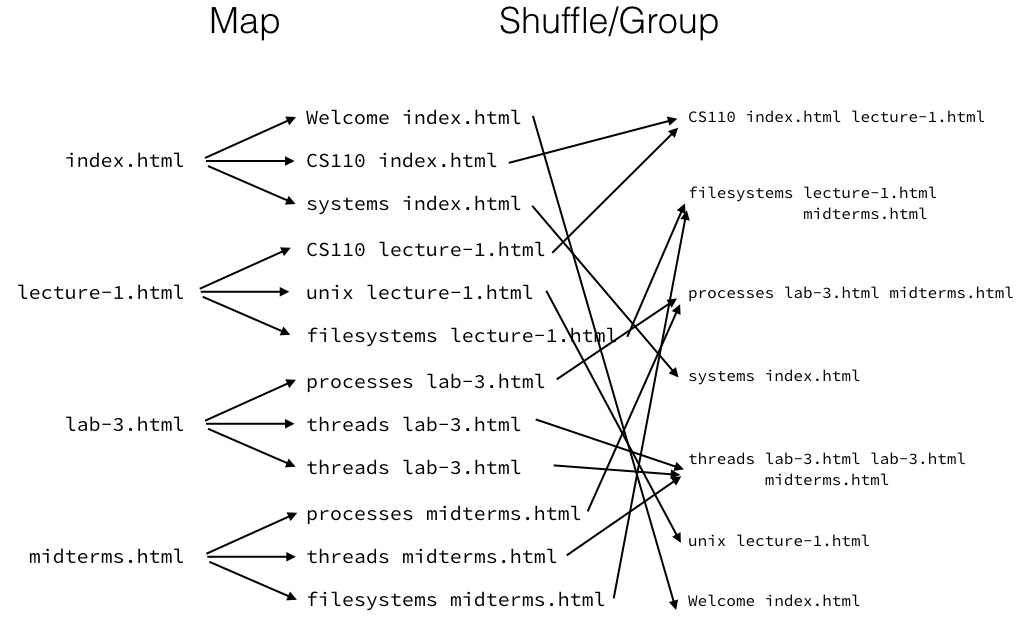
map(url:String, document:String):Void ->
for each w:word in document:
emit(w, url)
reduce(word:String, urls:List[String]):String ->
return urls.join(prefix=word, separator=' ')
Poll: What does this calculate?
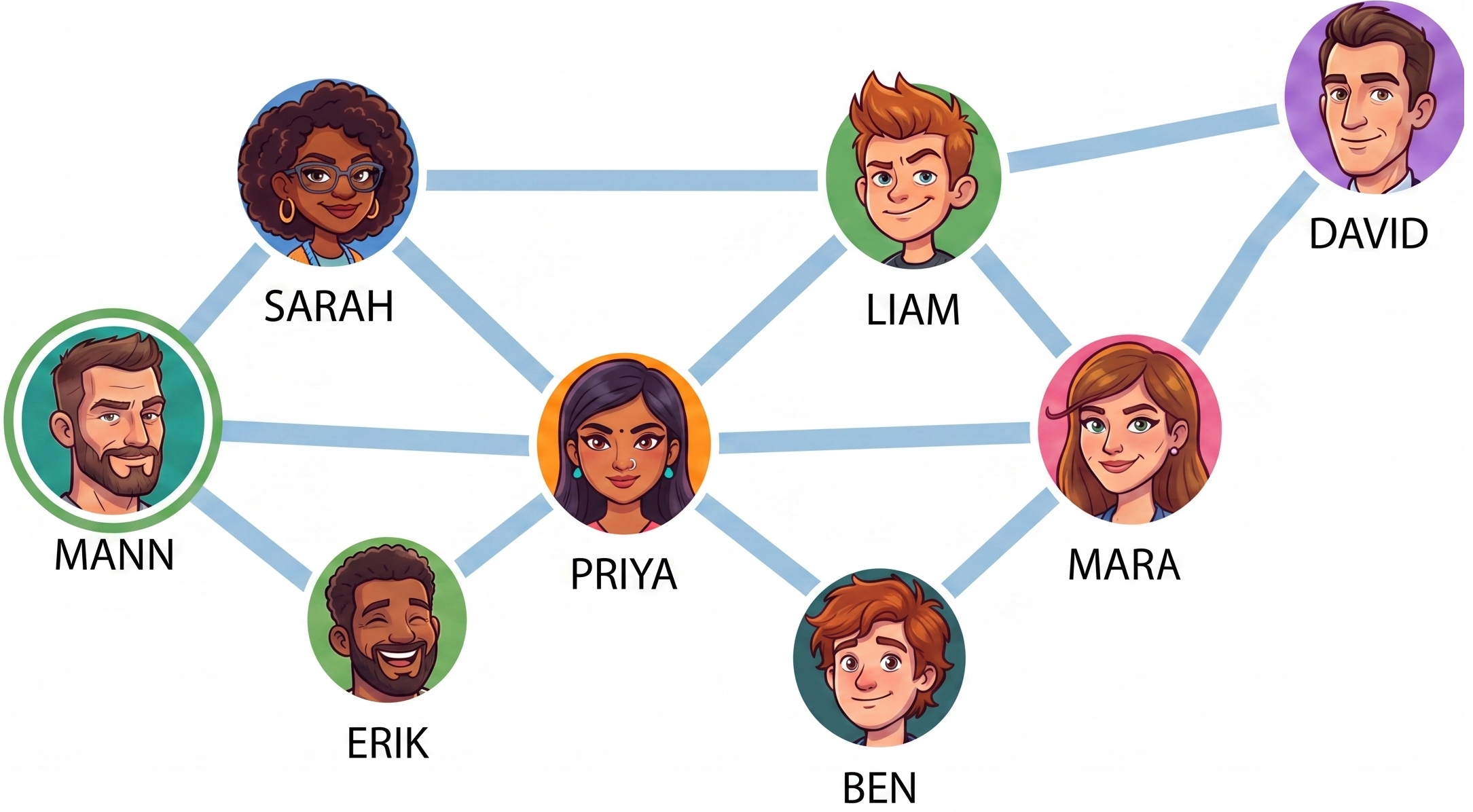

Text espertus to 22333 if the URL isn't working for you. https://pollev.com/espertus
// map over edges
map(p1:Person, p2:Person):Void ->
emit(p1, p2)
reduce(p: Person, persons:List[Person]):Int ->
return persons.length
A. How many connections each person has
B. How many nodes are in the graph
C. How many edges are in the graph
D. None of the above
MapReduce: How It Works
- Input is split into chunks, sent to different machines.
- Map workers process data, producing (key, value) pairs.
- Shufflers send data with the same key to reduce workers.
- Reduce workers write the output to GFS.
What Happens Behind the Scenes
The coordinator assigns tasks, monitors workers, and restarts failed ones — transparent to the programmer.
Your Laptop's File System Was Designed for a Different Workload
Most file systems are designed for open-edit-save workflows, of mostly small files.
| Your laptop's file system | Data processing workload |
|---|---|
| Small files (KB-MB) | Huge files (GB-TB) — a single crawl output can be terabytes |
| Random reads and writes | Append-only writes, sequential reads — scan start to finish |
| Open, edit, save, close | Write once, read many times, never modify |
| Permissions, directories, timestamps | Irrelevant at batch scale |
| 4KB blocks | Wasteful — 50GB file = 13 million blocks of bookkeeping |
Performance at Scale: Bigger Chunks and Data Locality
Why does GFS use larger chunks?
| Fixed cost per chunk | With 4KB blocks (100 TB) | With 64MB chunks (100 TB) | Reduction |
|---|---|---|---|
| Metadata entry in NameNode RAM | 26 billion entries | 1.6 million entries | 16,000x |
| Replication coordination (3 copies each) | 78 billion replica records | 4.8 million replica records | 16,000x |
| I/O round trips per read (NameNode lookup + DataNode setup) | 26 billion round trips | 1.6 million round trips | 16,000x |
We've seen this before: Batching and Locality (L34)
GFS Stores Data Across Thousands of Machines with Built-In Redundancy
Together, MapReduce + GFS = programmers write simple sequential functions, and the framework distributes execution across thousands of machines, handles failures, and manages storage transparently.
Pure Functions Make Re-Execution Safe — and Fault Tolerance Trivial
| Failure | Detection | Recovery | Why it works |
|---|---|---|---|
| Map worker dies | Coordinator pings periodically | Reassign task to another worker | Pure function (L5) → re-execution produces same output |
| Reduce worker dies | Coordinator pings periodically | Reassign reduce task | Idempotent (L33) → re-execution is safe |
| DataNode dies | NameNode detects missing heartbeat | Read from surviving replica (2 of 3 remain) | Redundancy (L35) → no single point of failure for data |
MapReduce Made Data Processing Cheap — So Total Consumption Exploded
Before MapReduce (early 2000s): processing the web index was a bespoke engineering effort — custom code, manual failure handling, weeks per pipeline.
MapReduce made it cheap: write two functions, submit a job, get results.
What happened: Per-job engineering cost dropped dramatically. Google ran thousands of MapReduce jobs daily by 2004. The efficiency gain per job was overwhelmed by the increase in total jobs. MapReduce consumed a significant fraction of Google's total compute.
L36 (Jevons' Paradox): Same pattern as Pawtograder — per-submission grading cost dropped, but unlimited submissions dramatically increased total compute. Efficiency is not sustainability.
MapReduce's Strengths Became Its Limitations as Context Changed
MapReduce's limitations drove Google to build successors:
| Limitation | Successor | What changed |
|---|---|---|
| Batch-only — cannot serve interactive queries | Dremel (interactive SQL) → BigQuery | Users needed answers in seconds, not hours |
| Two-function model — too restrictive for iterative algorithms | Systems supporting iterative computation (ML requires multiple passes over data) | Machine learning became a dominant workload |
| GFS single NameNode — metadata bottleneck at scale | Colossus — distributes metadata across multiple servers | File system grew beyond one NameNode's capacity |
Open Source Made MapReduce Sustainable Beyond Google
Google published the MapReduce (2004) and GFS (2003) papers — but kept the code proprietary. Doug Cutting and Mike Cafarella read the papers and built Apache Hadoop: an open source implementation.
| What happened | Sustainability dimension |
|---|---|
| Yahoo, Facebook, and hundreds of companies adopted Hadoop | Economic — shared infrastructure cost, no single-vendor lock-in |
| Entire ecosystem grew: Spark, Hive, HBase, Kafka | Technical — clean programming model enabled open source reimplementation |
| Google's proprietary system was replaced internally — but the ideas live on in open source | Social — any organization can process data at scale, not just Google |
| Same pattern: Google's Borg → open source Kubernetes (container orchestration for everyone) | Technical — clean abstractions enable reimplementation; Borg's ideas power every cloud provider |
| Hadoop and K8s clusters consume enormous energy worldwide | Environmental — Jevons' paradox again, now at industry scale |
The Inventors of MapReduce
"DEC was one of the first companies to build a successful web search engine — AltaVista, which came out of the Western Research Lab — and at least in the beginning, the entire thing ran on a single DEC machine. But Google eclipsed AltaVista in large part because it turned this model on its head. Rather than using big, beefy machines to run its search engine, it broke its software into pieces and spread them across an army of small, cheap machines. This is the fundamental idea behind GFS, MapReduce, and BigTable — and so many other Google technologies that would overturn the status quo."
Jeff Dean Facts
- The rate at which Jeff Dean produces code jumped by a factor of 40 in late 2000 when he upgraded his keyboard to USB 2.0.
- Jeff Dean once failed a Turing test when he correctly identified the 203rd Fibonacci number in less than a second.
- Google search went down for a few hours in 2002, and Jeff Dean started handling queries by hand. Search Quality doubled.
- Jeff Dean's infinite loops run in 5 seconds.
Jeff Dean (2020)

Reputations

“It takes 20 years to build a reputation and five minutes to ruin it. If you think about that, you'll do things differently.”
CC-BY 2.0 Marco Verch

Lessons
- Keep an eye out for paradigm shifts. Don't solve today's problems with yesterday's tools.
- Software architecture comes out of requirements.
- "Luck is what happens when preparation meets opportunity." — Seneca
- Act in accordance with your values.
Bonus Slide
![Graphic with header: 'map, filter, and reduce explained with emoji'.
map([cow, potato, chicken, corn], cook) => [hamburger, fries, drumstick, popcorn]
filter([hamburger, fries, drumstick, popcorn], isVegetarian) => [fries, popcorn]
reduce([hamburger, fries, drumstick, popcorn], eat) => poop](/CS3100-Spring-2026/img/lectures/web/l38-map-filter-reduce-emojis.png)