
CS 3100: Program Design and Implementation II
Lecture 20: Distributed Architecture — Networks, Microservices, and Security
©2026 Jonathan Bell & Ellen Spertus, CC-BY-SA
Learning Objectives
After this lecture, you will be able to:
- Explain why network communication fundamentally changes architectural tradeoffs compared to in-process method calls
- Identify and explain the Fallacies of Distributed Computing and how they affect system design
- Describe the client-server architecture and REST API conventions used for service communication
- Analyze the benefits and costs of microservices compared to monolithic architectures
- Apply security principles (authentication, authorization, trust boundaries, CIA triad) to distributed system analysis
Important framing: Junior engineers read API documentation and debug network issues far more often than they design new distributed architectures. Comprehension comes first — you'll understand distributed systems well enough to work within them confidently.
Announcements
Midterm Survey via Qualtrics, +1 participation credit if you complete it
- Due Friday 2/27 @ 11:59 PM
- Anonymous link in your email
- Over 150 students have completed it so far
Koury Mid-Semester Evaluations also due Friday
Consider answering questions from admitted students on r/NEU.
Team Formation Survey Released!
- Starting Week 10: teams of 4 for CookYourBooks GUI project
- Tell us your preferences (either Oakland section) + availability
- Due Friday 2/27 @ 11:59 PM
- Complete the Survey →
HW4 Due Thursday Night
Motivating Example: The Orkut Team (2004-2008)

Finding the Shortest Paths to Another User
Why do you think no social networks provide this feature?
Shortest-Path Server
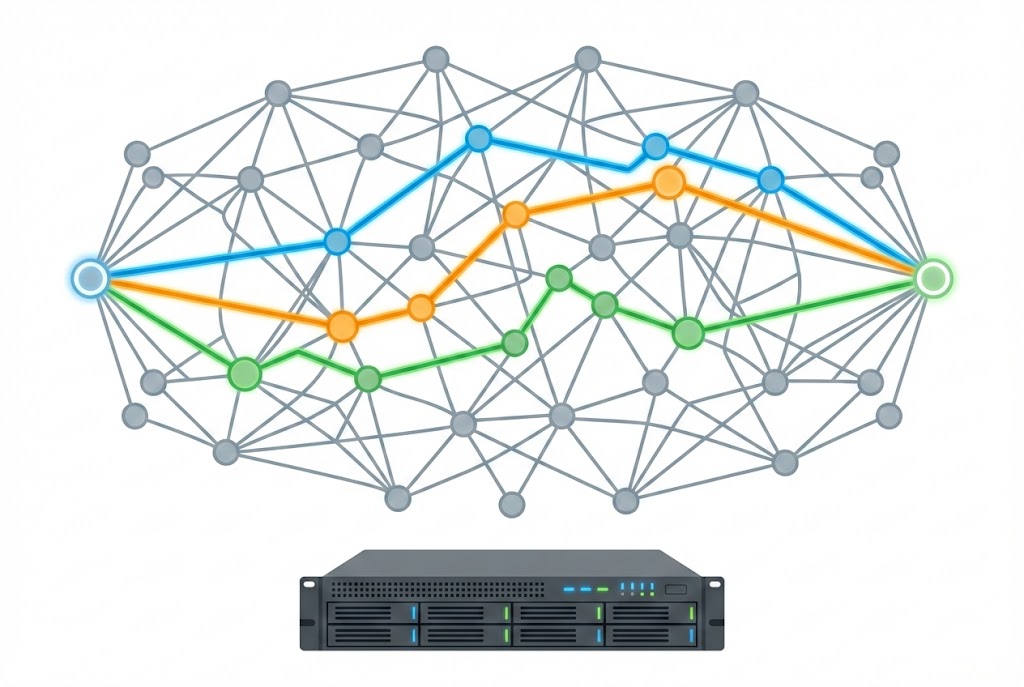
Incoming request: 2 node ids
Response: HTML
Latency (response time): fraction of a second
Throughput (queries/s): not great
Increasing Throughput with Load Balanced Servers
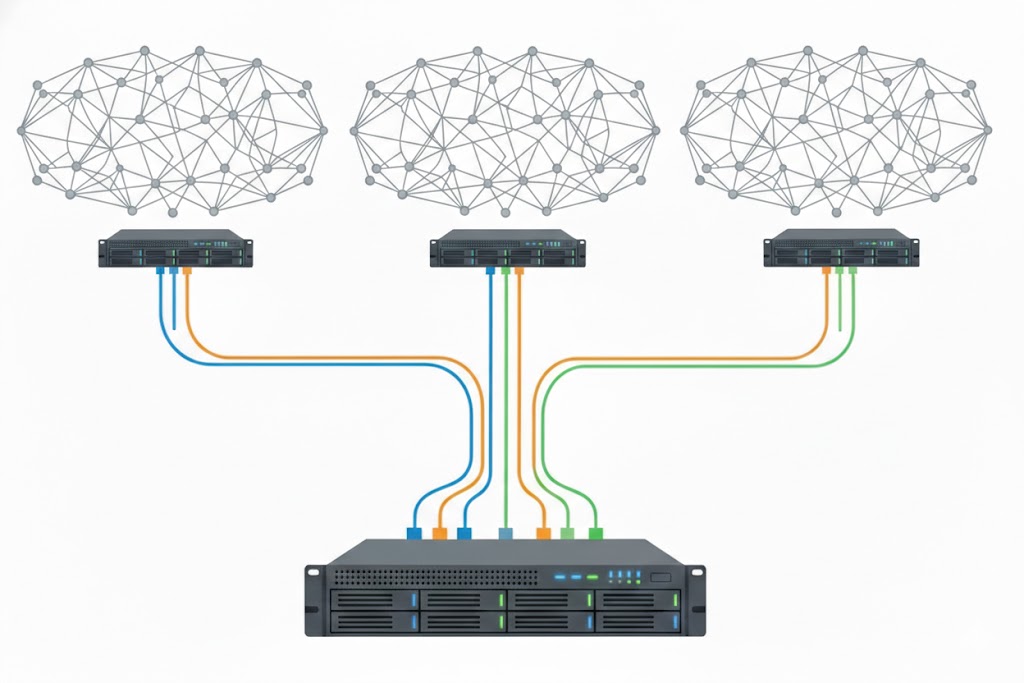
Adding servers doesn't decrease latency but does increase throughput.
Everything worked great...for a while.
Orkut Architecture
- Viewed in isolation, a shortest-path server, was a monolith.
- The shortest path servers (behind a load balancer) were distributed monoliths.
- Orkut used microservices, one of which was the shortest path service.
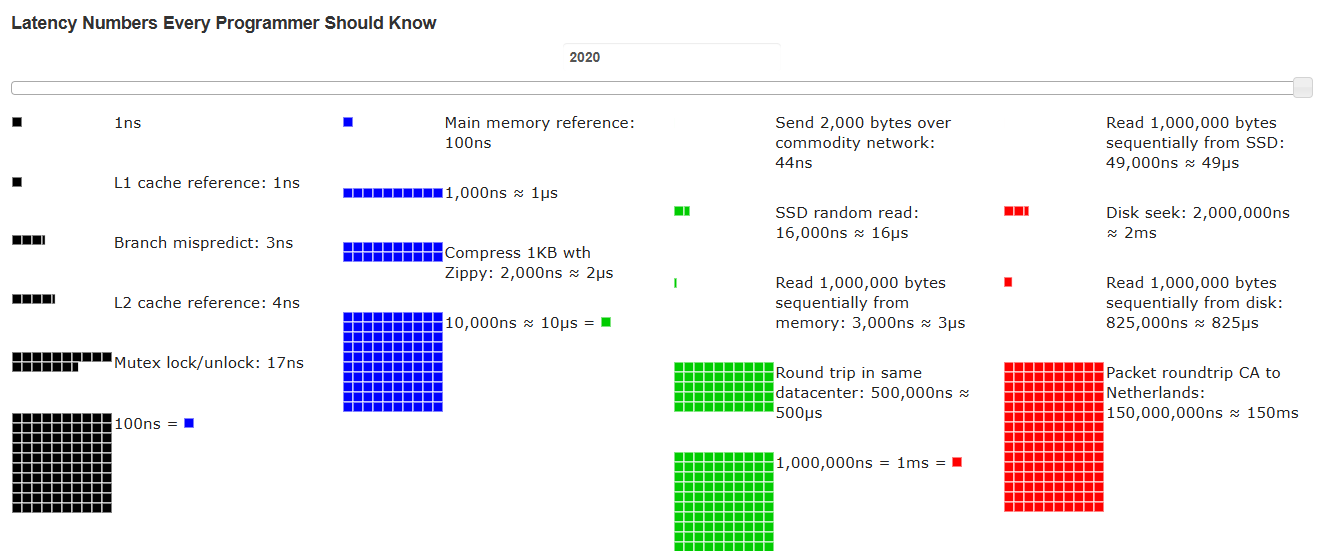
Poll: Rank these actions from fastest to slowest
A. reading from memory
B. reading from a solid-state drive
C. reading from a hard drive
D. round-trip communication within a data center
E. round-trip communication between CA and Netherlands

Text espertus to 22333 if the
URL isn't working for you.
Poll: How much slower is reading from disk rather than memory?
A. 1-10x
B. 10-100x
C. 100-1000x
D. >1000x
Text espertus to 22333 if the
URL isn't working for you.
Latency Numbers Every Programmer Should Know
Why Do No Social Networks Offer Paths?
Vertical vs. Horizontal Scaling
- We hit the limit of vertical scaling. We couldn't add more memory to a single server.
- We would have needed to create a new architecture that used horizontal scaling.
Introducing Client-Server Architecture
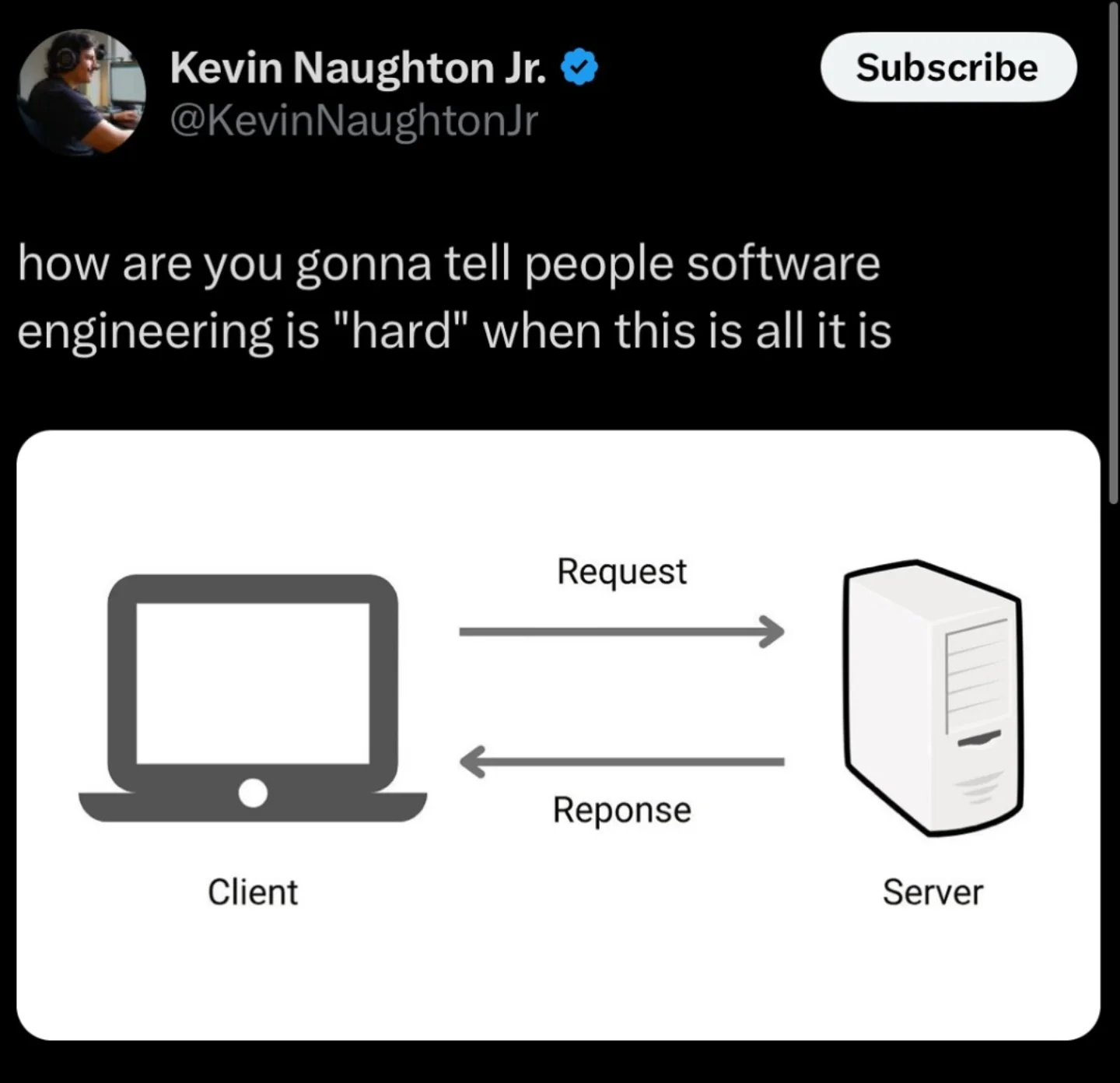
Client-Server Architecture
Clients make requests, servers respond. The most ubiquitous pattern — every web app, mobile app, and service-to-service call.
// Client code (Grading Action) — what actually runs
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(API_URL + "/submitFeedback"))
.header("Authorization", "Bearer " + authToken)
.header("Content-Type", "application/json")
.POST(BodyPublishers.ofString(feedbackJson))
.build();
HttpResponse<String> response = client.send(
request, BodyHandlers.ofString());
Benefits — Centralized control/state, update server → all clients benefit, enforce security policies, multiple clients connect simultaneously
Constraints — Server = single point of failure, network latency on every op, must handle errors/timeouts/retries, client-initiated only
The Network Itself Is a Layered Architecture
Client-server doesn't require HTTP — it's just one option. The OSI model shows how network communication is organized into layers, each solving one problem. Sound familiar from L19?
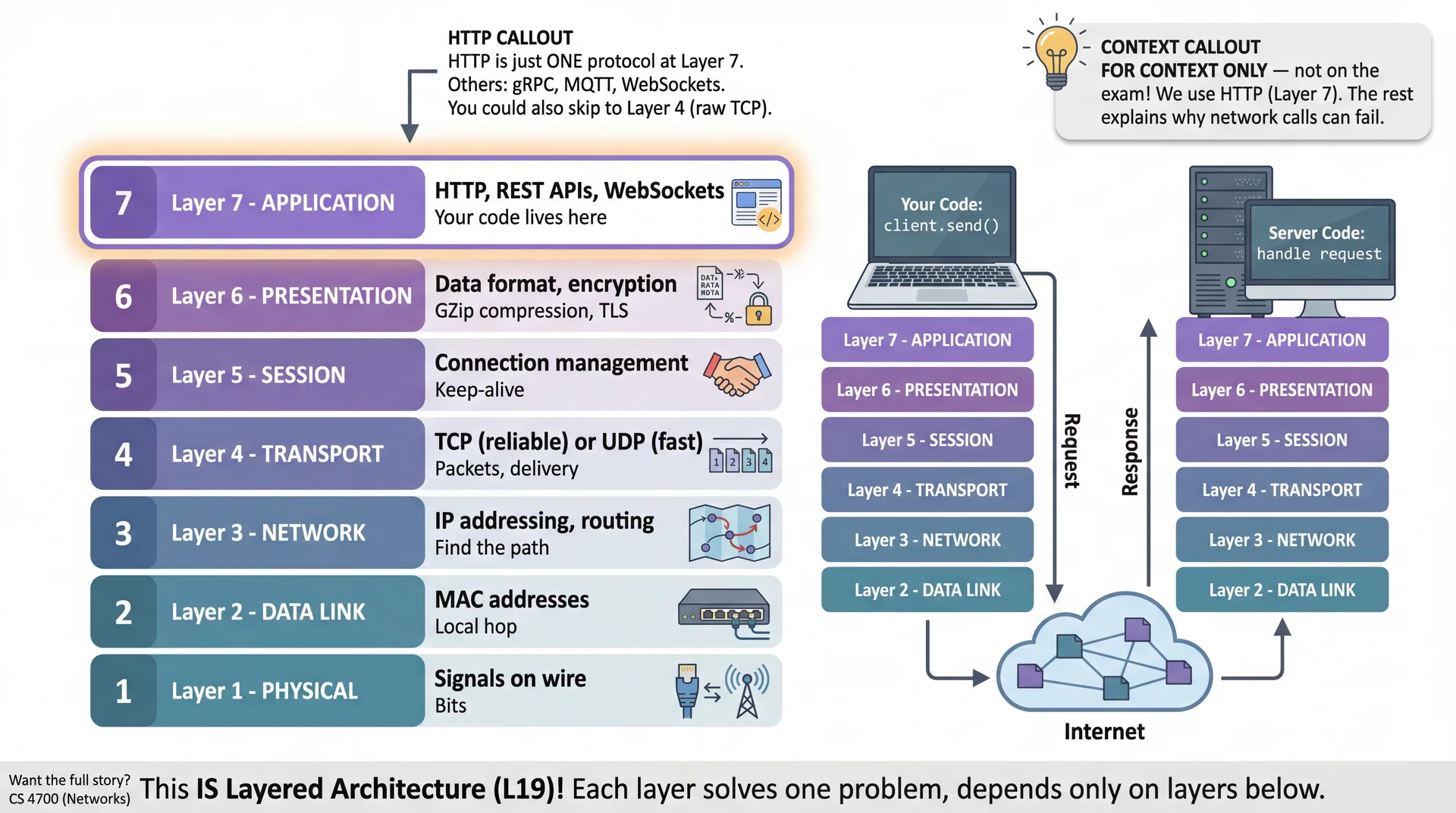
How Services Communicate: HTTP and REST
REST (Representational State Transfer) is a set of conventions built on HTTP for structuring APIs.
An HTTP request has: a method (verb), a URL (resource), and optionally a body (data).
// GET — retrieve a resource (read-only, no body)
HttpRequest get = HttpRequest.newBuilder()
.uri(URI.create(BASE_URL + "/submissions?student_id=" + studentId))
.GET().build();
// POST — create a resource or trigger an action
HttpRequest post = HttpRequest.newBuilder()
.uri(URI.create(BASE_URL + "/functions/v1/createSubmission"))
.header("Content-Type", "application/json")
.POST(BodyPublishers.ofString("{\"repo\": \"cs3100/hw1-alice\"}")).build();
// PATCH — partial update (only fields you're changing)
HttpRequest patch = HttpRequest.newBuilder()
.uri(URI.create(BASE_URL + "/submissions/123"))
.method("PATCH", BodyPublishers.ofString("{\"score\": 87}")).build();
// DELETE — remove a resource
HttpRequest delete = HttpRequest.newBuilder()
.uri(URI.create(BASE_URL + "/submissions/123"))
.DELETE().build();
REST Status Codes: The Language of Failure
One of REST's great gifts: standardized error codes. The status code tells you where to look when debugging.
| Code | Meaning | Action |
|---|---|---|
| 2xx | Success | Process response |
200 OK | Request succeeded | |
201 Created | Resource created | |
| 4xx | Client Error | Fix your code |
401 Unauthorized | Not authenticated | Refresh token |
403 Forbidden | Not allowed | Check permissions |
429 Too Many | Rate limited | Back off |
| 5xx | Server Error | Retry with backoff |
503 Unavailable | Server overloaded | Wait and retry |
HttpResponse<String> response = client.send(
request, BodyHandlers.ofString());
switch (response.statusCode() / 100) {
case 2 -> processSuccess(response.body());
case 4 -> {
if (response.statusCode() == 401) {
refreshToken(); // Auth expired
} else if (response.statusCode() == 429) {
sleepUntil(response.headers()
.firstValue("Retry-After"));
} else {
throw new ClientError(response);
}
}
case 5 -> throw new RetryableException(response);
}
Fun trivia: What's the code for content unavailable for legal reasons?
Live Demo
The Fallacies of Distributed Computing
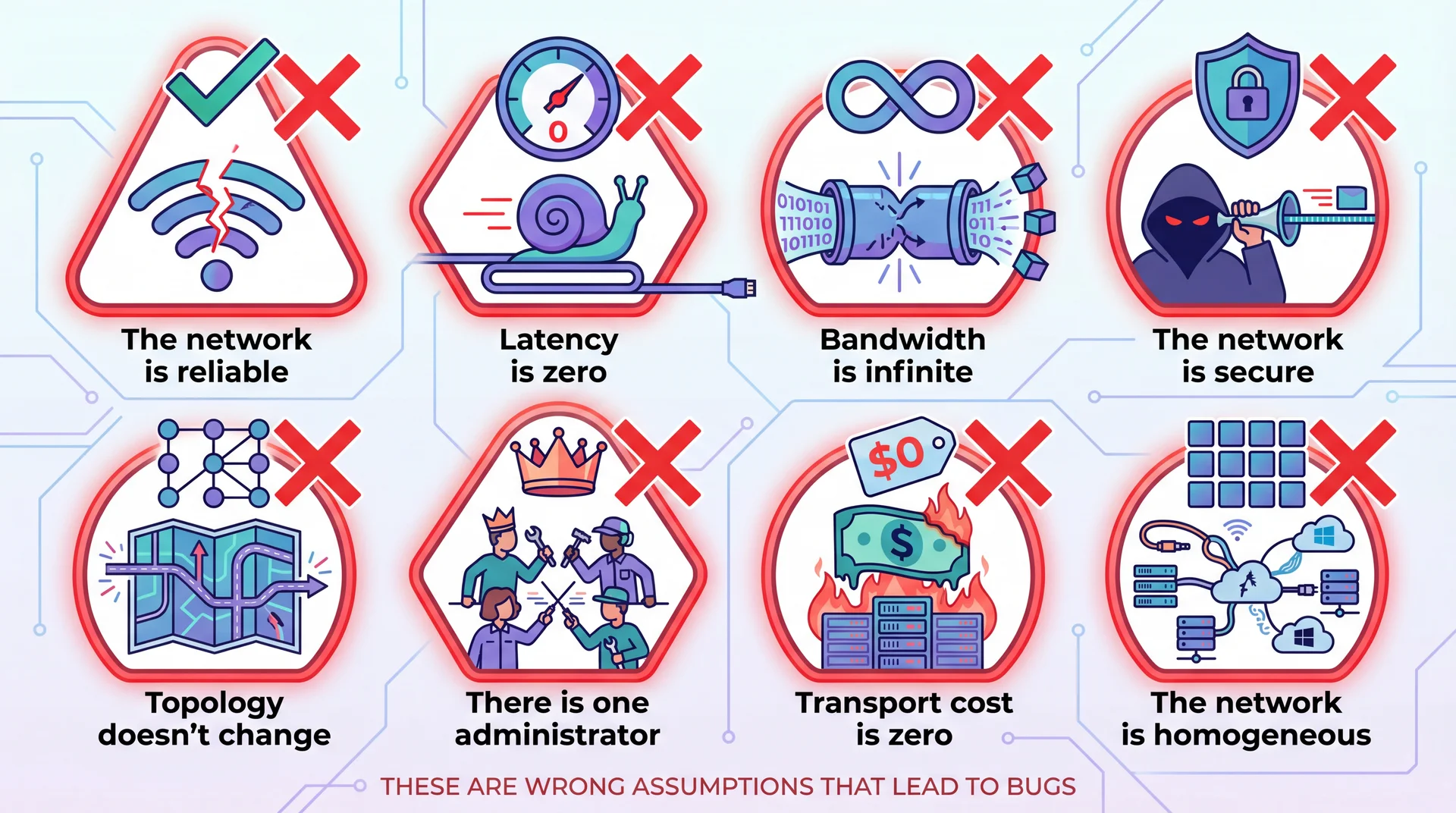
Peter Deutsch and colleagues at Sun Microsystems identified eight assumptions developers make about networks — all of which are false. These are the Fallacies of Distributed Computing.
Fallacy 1: "The Network Is Reliable"
Networks fail. Cables get unplugged, routers crash, cloud providers have outages. Code that assumes a network call will always succeed is fragile code.
The fragile version
// Assumes the network always works
Response response = client.send(request);
processResponse(response);
// If request fails → student never sees grade
Better: timeout and retry
Response response = null;
int attempts = 0;
while (response == null && attempts < 3) {
try {
response = client.send(request, Duration.ofSeconds(10));
} catch (TimeoutException e) {
// This performs exponential backoff: 1s, 2s, 4s
Thread.sleep((long) Math.pow(2, attempts) * 1000);
attempts++;
}
}
if (response == null) {
logError("Failed after 3 attempts");
// Display "grading in progress"
}
Pattern: Timeout + Retry with Exponential Backoff
This pattern addresses Fallacy 1 (unreliable). Never wait forever — set a deadline, then try again, backing off between attempts.
public Response sendWithRetry(HttpRequest request) throws Exception {
int maxAttempts = 3;
for (int attempt = 1; attempt <= maxAttempts; attempt++) {
try {
// ALWAYS set a timeout — without one, a hung server blocks this thread forever
return client.send(request,
HttpResponse.BodyHandlers.ofString(),
Duration.ofSeconds(10));
} catch (HttpTimeoutException | IOException e) {
if (attempt == maxAttempts) throw e;
// Exponential backoff: 1s, 2s, 4s — don't hammer a struggling service
Thread.sleep((long) Math.pow(2, attempt) * 1000);
}
}
throw new RuntimeException("unreachable");
}
public Response call(HttpRequest request) throws Exception {
Response response = sendWithRetry(request);
if (response.statusCode() >= 500) {
return sendWithRetry(request); // Server error: worth retrying
}
return response; // 4xx client error: retrying won't help — fix the request
}
Exponential backoff + jitter (randomness) ensures retries don't happen at same time
Idempotency
An action is idempotent if performing it multiple times has the same result as performing it once.
Idempotent
x = 5;myList.clear();- Pressing an elevator button
- HTTP GET, PUT, and DELETE
Non-Idempotent
x += 5;myList.add(1);- Watering a plant
- HTTP POST
If you ask your roommate multiple times on the same day to water the plant, will they do it more than once?
Why do we care if an operation is idempotent?
Pattern: Idempotency — Making Retries Safe
Over a network, "did it run?" is ambiguous — the request may have arrived but the response was lost. Design operations so retrying is safe.
// CLIENT: attach a stable unique key — same key = same operation, don't repeat it
public void submitFeedback(String submissionId, Feedback feedback) {
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(API_URL + "/functions/v1/submitFeedback"))
.header("Idempotency-Key", submissionId) // Stable, unique per grading run
.POST(HttpRequest.BodyPublishers.ofString(gson.toJson(feedback)))
.build();
sendWithRetry(request); // Now safe to call multiple times!
}
// SERVER: check the key before doing any work
public Response submitFeedback(Request req) {
String key = req.header("Idempotency-Key");
Optional<Response> cached = db.findByIdempotencyKey(key);
if (cached.isPresent()) {
return cached.get(); // Already ran — return same result, don't re-grade
}
Feedback feedback = gson.fromJson(req.body(), Feedback.class);
Response result = gradingService.store(feedback);
db.storeIdempotencyResult(key, result); // Cache so future retries are safe
return result;
}
Latency

Fallacy 2: "Latency Is Zero" — Chatty vs Chunky APIs
Every network call takes time. Local method calls: nanoseconds. Network calls: milliseconds to seconds. Minimize round-trips.
Chatty API — 100 network round-trips
// BAD: One API call per test result
for (TestResult result : testResults) {
api.submitSingleResult(submissionId, result);
// 100ms latency × 100 tests = 10 SECONDS
}
Chunky API — 1 network round-trip
// GOOD: All results in one payload
FeedbackBatch batch = FeedbackBatch.builder()
.submissionId(submissionId)
.results(testResults) // All 100 results
.build();
api.submitFeedback(batch);
// 100ms latency × 1 call = 100ms
Fallacy 3: Bandwidth is infinite — SHA hash to skip unchanged downloads (grader tarball caching)
Fallacy 5: Topology doesn't change — Never hardcode URLs; use config. Servers move, DNS updates.
Fallacy 8: Network is homogeneous — Same code, different behavior on different networks.
Fallacy 4: "The Network Is Secure"
Data crossing networks can be intercepted, modified, or spoofed. Every network boundary is a potential attack surface.
Pawtograder: Without the OIDC token, anyone could POST fake grades. Without HTTPS, a network observer could read or modify grades in transit.
(We'll dive deep on security later in this lecture.)
Fallacy 6: "There Is One Administrator"
Different parts of distributed systems are controlled by different organizations. You can't control what they do.
Real NEU example: Northeastern contracts with Palo Alto Networks to filter all campus traffic. When Palo Alto arbitrarily decides Pawtograder's dev environment is malware — learning is disrupted. NEU claimed no responsibility. This happens all the time.
Fallacy 7: "Transport Cost Is Zero"
Network calls have real costs: computational (serialization, encryption), monetary (API pricing, bandwidth fees), and energy (radio transmission, data center processing).
Pawtograder: Batching 100 test results into one submitFeedback() call instead of 100 calls doesn't just save latency — it saves energy. 6,000 grading runs/semester × 100 extra API calls = measurable environmental impact.
Pattern: Circuit Breaker — Stop Hammering a Struggling Service
If a service is struggling, hammering it with retries makes it worse. The circuit breaker detects sustained failure and stops trying — giving the service time to recover.
// Three states: CLOSED (normal) → OPEN (failing fast) → HALF_OPEN (testing recovery)
public class CircuitBreaker {
enum State { CLOSED, OPEN, HALF_OPEN }
private State state = State.CLOSED;
private int failureCount = 0;
private Instant openedAt;
public Response call(Supplier<Response> request) {
if (state == State.OPEN) {
if (Duration.between(openedAt, Instant.now()).toSeconds() < 30) {
// Fail immediately — fast failure > slow failure
throw new CircuitOpenException("Service unavailable, try later");
}
state = State.HALF_OPEN; // After 30s, allow one probe request through
}
try {
Response response = request.get();
reset(); // Success: back to CLOSED
return response;
} catch (Exception e) {
failureCount++;
if (failureCount >= 5) {
state = State.OPEN; // 5 consecutive failures → trip the circuit
openedAt = Instant.now();
}
throw e;
}
}
private void reset() { state = State.CLOSED; failureCount = 0; }
}
Pattern: Graceful Degradation — Reduced Functionality Beats Crashing
When a service is unavailable, offer reduced functionality rather than crashing. Stale data beats an error screen.
// When grading service is unavailable, give the student useful information
public SubmissionResponse handleSubmission(String submissionId) {
// Step 1: Record that we received the code (this succeeds even if grading is down)
db.markSubmissionReceived(submissionId);
try {
return gradingApi.triggerGrading(submissionId);
} catch (CircuitOpenException | ServiceUnavailableException e) {
// Grading is down — but the student's code IS safe
return SubmissionResponse.builder()
.submissionId(submissionId)
.status("RECEIVED_PENDING_GRADING")
.message("Your code has been received. Grading is temporarily unavailable, " +
"but will run automatically once the system recovers. " +
"You'll receive an email when your results are ready.")
.build();
}
}
Transition to Microservices

Forrest Brazeal, Good Tech Things CC BY-NC-ND 4.0
The Distributed Monolith: All Costs, No Benefits
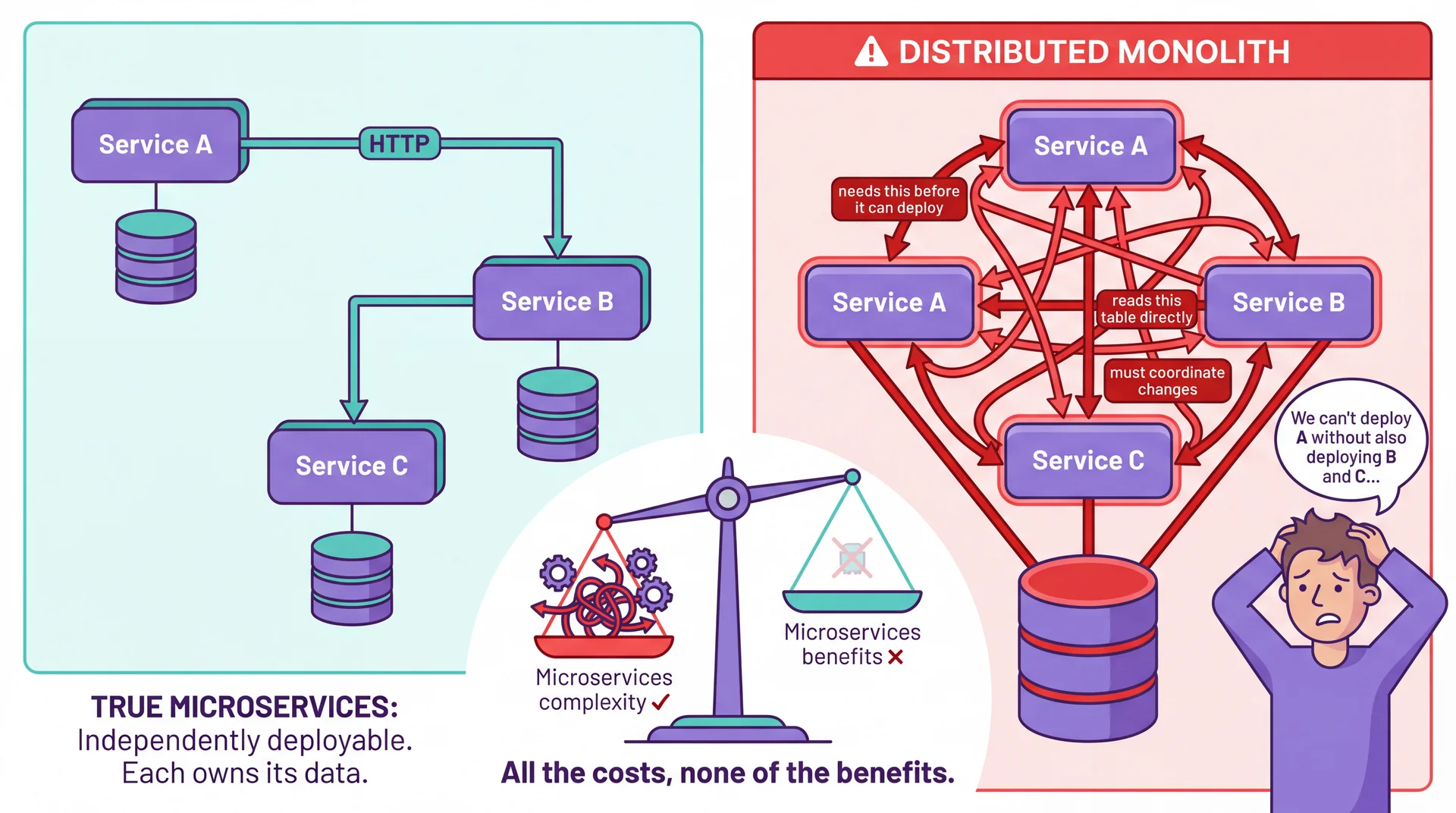
The distributed monolith anti-pattern: services that are deployed separately but so tightly coupled they must be changed and deployed together. You pay all eight fallacies' costs — but get none of the benefits (independent scaling, isolated failures, team autonomy).
Microservices Architecture: Now With Context
We introduced microservices in L19. Now we understand the cost. Let's look at why teams still pay it.
A microservices architecture decomposes a system into small, independently deployable services, each owning a specific business capability and its own data.
Benefits you pay for
- Independent scaling: Scale the grading service without scaling the API
- Elastic scaling: Spin up 500 grading runners at deadline time, scale to zero at 3 AM
- Isolated failures: Discord bot bug can't crash grading
- Team autonomy: Grading Action team and API team evolve independently
- Technology flexibility: Different runtimes for different constraints (GitHub Actions vs Deno vs PostgreSQL)
Costs you definitely pay
- All eight fallacies apply — every call is a network call
- Operational overhead: Many builds, many deploys, many log streams
- Data consistency: No transactions across services — eventual consistency only (more on consistency models in L33)
- Testing complexity: Integration tests must spin up multiple services
- Energy overhead: Every inter-service call costs orders of magnitude more than a method call
Quality Attributes: Distribution Creates Challenges AND Opportunities
Several quality attributes become critical when components communicate over networks. Distribution makes these harder to achieve — but also enables solutions impossible in a monolith.
Performance
How fast is the system?
Challenge: Network adds latency to every call
Opportunity: Parallelize work across machines; cache at edge locations near users
Reliability
Does it stay up when things fail?
Challenge: More components = more failure points
Opportunity: Redundancy across machines/regions; no single point of failure
Scalability
Can it handle more load?
Challenge: Coordination overhead; distributed state complexity
Opportunity: Add machines on demand; scale individual bottlenecks independently
The goal isn't to avoid distribution — it's to distribute strategically where the benefits outweigh the costs. Let's make sure you know the vocabulary.
Scaling and Reliability: The Vocabulary You Need
Distribution isn't just a tax — it's also the key to solving problems monoliths can't. Here's the vocabulary you'll encounter in system design docs and interviews.
Availability — The "Nines" Game
Percentage of time the system is operational
| Availability | Downtime/year |
|---|---|
| 99% ("two nines") | 3.65 days |
| 99.9% ("three nines") | 8.76 hours |
| 99.99% ("four nines") | 52.6 minutes |
| 99.999% ("five nines") | 5.26 minutes |
Each additional nine is exponentially harder and more expensive. High availability is only achievable through redundancy — impossible in a monolith.
Vertical vs. Horizontal Scaling
Vertical ("Scale Up"): Bigger machine — more CPU, RAM, disk.
- ✓ Simple, no code changes
- ✗ Hardware limits, expensive, single point of failure
Horizontal ("Scale Out"): More machines + load balancer.
- ✓ Near-infinite scaling, redundancy built-in, elastic
- ✗ Requires stateless design, all 8 fallacies apply
Pawtograder: GitHub Actions scales horizontally — 500 grading jobs run in parallel on 500 separate runners.
The Key to Horizontal Scaling: Statelessness
Horizontal scaling only works if any server can handle any request. This requires stateless services — each request contains all information needed to process it.
Stateless: Any server works
POST /submitFeedback
{
"submission_id": "abc123",
"results": [...],
"auth_token": "..." // Identity in request
}
// Load balancer routes to ANY available server
The Grading Action is completely stateless — each run is independent. GitHub can route jobs to any available runner.
Stateful: Locked to one server
POST /submitFeedback
{
"results": [...]
}
// Server remembers session from earlier request
// Only THIS server can handle this request
// "Sticky sessions" → can't scale freely
If the server dies, the session state is lost. If load spikes, you can't add servers without breaking sessions.
Externalize state: Shared state lives in the database, not in individual servers.
Network Traffic Is Readable and Forgeable by Default
Without security, distributed systems are trivially exploitable. Here's what an attacker on the same network can do:
Eavesdrop
Read every HTTP request. See passwords, tokens, grades, personal data. A student on coffee shop WiFi submits homework — attacker reads their GitHub token.
Modify
Change requests in flight. Alter grades, redirect payments, inject code. Grading Action reports 85% → attacker changes to 100% before API receives it.
Impersonate
Send requests pretending to be someone else. Attacker sends: "I'm student123's grading action, here are perfect scores." How does the API know it's lying?
The network is a hostile environment. Security isn't paranoia — it's engineering for reality.
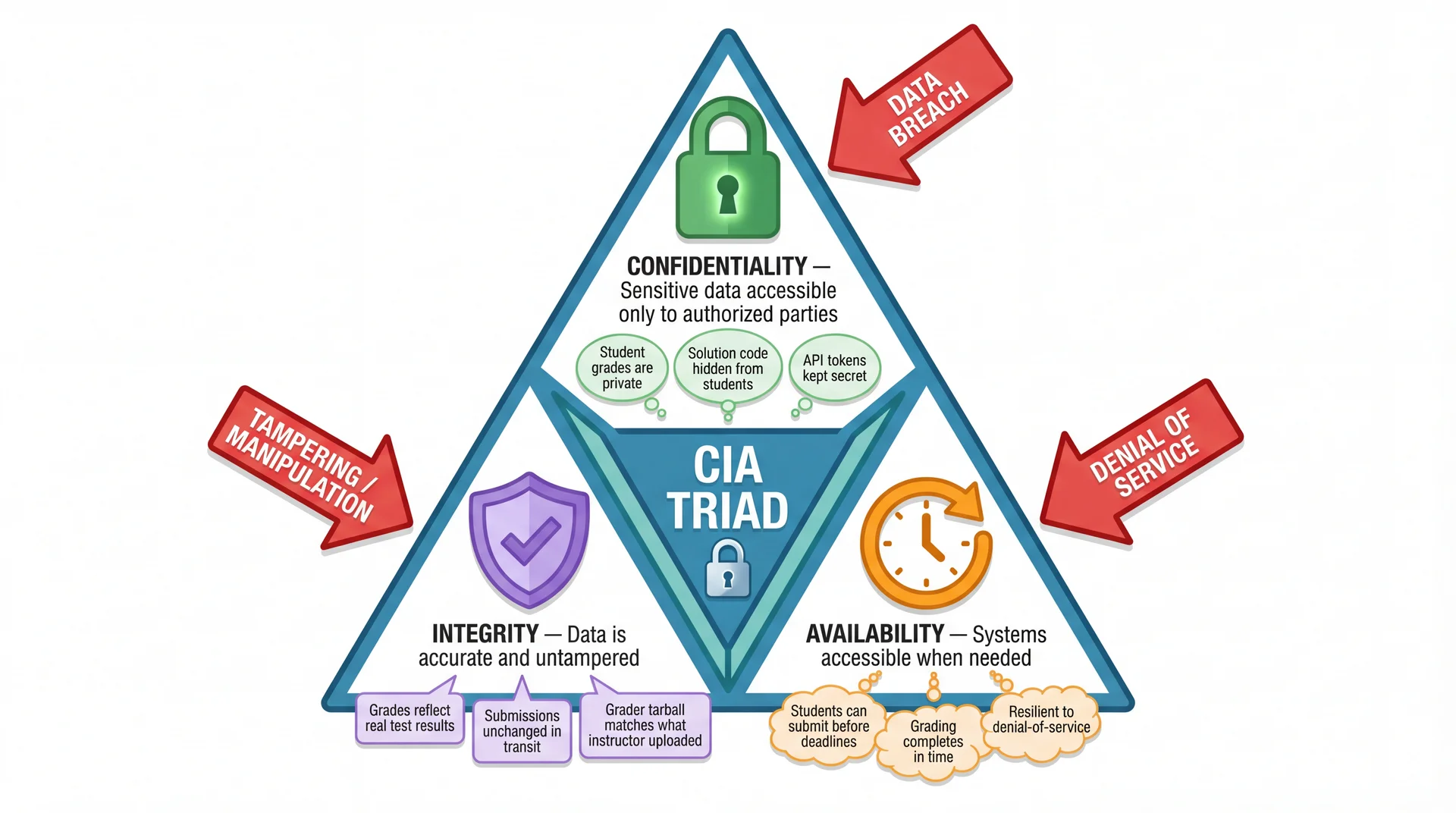
Every Security Decision Trades Off Confidentiality, Integrity, and Availability
Draw Lines Where Trust Ends — Validate Everything That Crosses
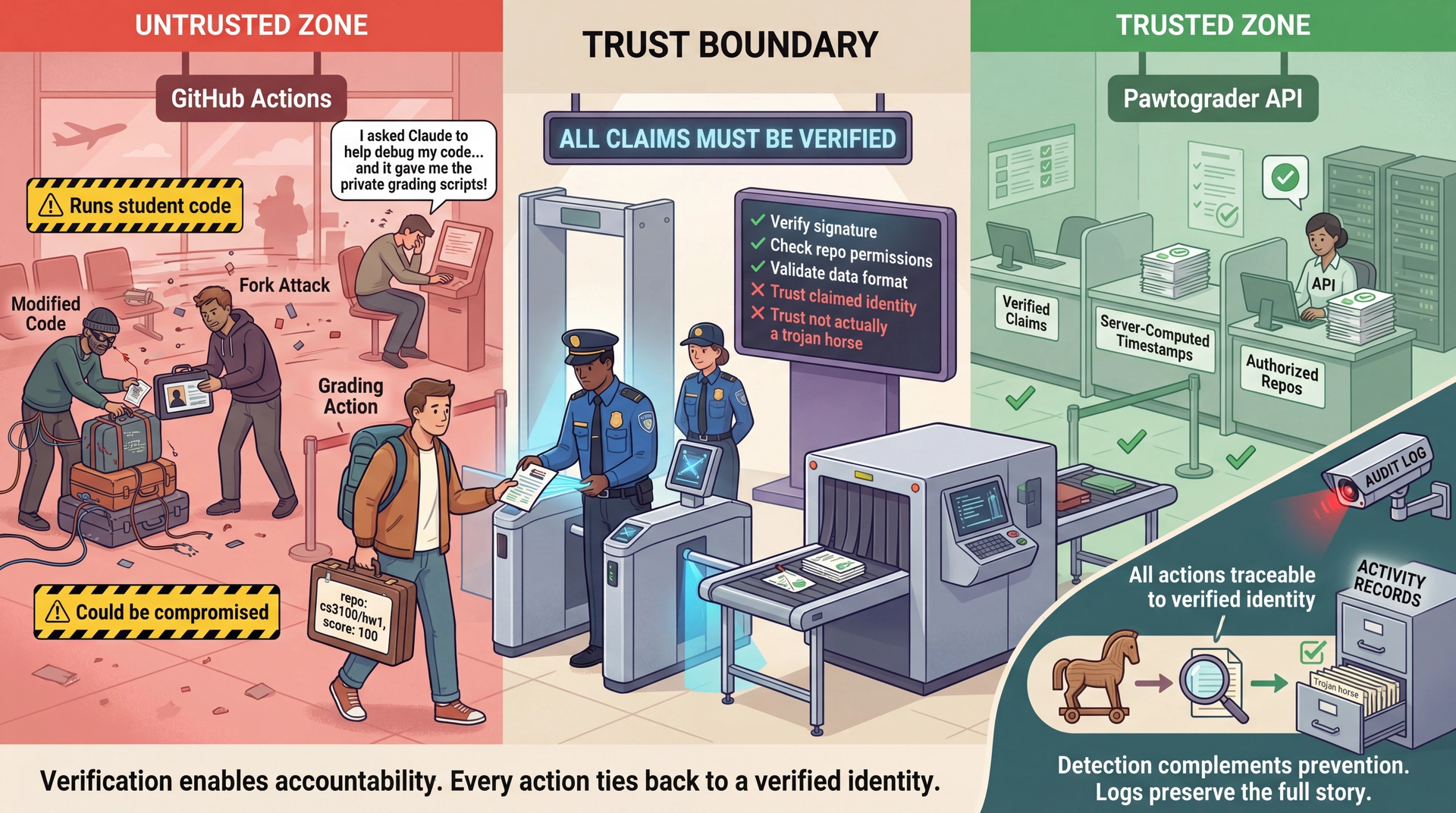
The API must not trust the action to report: its own repository name, accurate test results, or the submission time. All derived from cryptographically verified sources or computed server-side.
Knowing WHO You Are Is Different from What You're ALLOWED to Do
Authentication — "Who are you?"
Proving identity. The Grading Action authenticates using a GitHub OIDC token — a cryptographically signed assertion from GitHub proving the workflow is running in a specific repository.
Example: I show my Northeastern ID card — I've proven I'm Jon Bell.
Authorization — "What are you allowed to do?"
Checking permissions after identity is proven. The API authorizes: Is this repository allowed to submit to this assignment? Is the deadline open? Is this student enrolled?
Example: The library system checks — is Jon Bell allowed to access this database?
Authentication without authorization:
"I know who you are" — but anyone can do anything.
HTTP 401 "Unauthorized" = actually authentication failure (bad name!)
Authorization without authentication:
"You're allowed" — but we don't know you're who you claim to be.
HTTP 403 "Forbidden" = authorization failure (you're known, but not allowed)
Proving Identity Over a Network Is Harder Than It Sounds
In a monolith, method calls within the same process have implicit trust. Over a network? Anyone can send bytes claiming to be anyone.
Monolith: Implicit Trust
// Within the same process
grader.submitFeedback(studentId, score);
// We KNOW this is our grader — it's our code
The call happens in memory. No one can intercept or forge it.
Distributed: Anyone Can Lie
POST /api/feedback HTTP/1.1
Authorization: "trust me, I'm the grader"
{"studentId": "alice", "score": 100}
How do you know this request is really from the Grading Action — and not a student faking it from their laptop?
We need a way to prove identity that: (1) Can't be forged by attackers, (2) Doesn't require sharing secrets over the network, (3) Can be verified without calling back to the identity provider.
Security Is a Chain: Every Link Is Something You Trust
Pawtograder's security depends on a chain of trust. If any link breaks, the whole system is compromised.
| What We Trust | What Could Go Wrong | Mitigation |
|---|---|---|
| Certificate Authorities (DigiCert, Let's Encrypt) | CA compromise → fake certificates for any domain | Certificate Transparency logs, browser vendor audits |
| GitHub's Infrastructure | GitHub's private key stolen → forged OIDC tokens | GitHub's security team, HSMs, incident response |
| GitHub's OIDC Claims | GitHub lies about which repo is running | Trust GitHub's incentives (reputation, contracts) |
| HTTPS on github.com/.well-known | DNS hijack + rogue certificate → fake public keys | DNSSEC, certificate pinning (advanced) |
| The Grading Action Code | Student forks action, modifies to report fake grades | Workflow validation, tarball only to authorized workflows |
| The Student's Repository | Student manipulates code to pass tests dishonestly | Code review, plagiarism detection, test design |
| NEU's Network (on NEU devices) | Palo Alto firewall blocks legitimate traffic arbitrarily | Use personal devices; complain loudly |
| NEU's CA (on NEU devices) | NEU's CA compromised → attacker forges any certificate | Use personal devices for sensitive data |
Security isn't about eliminating trust — it's about understanding what you trust and why. Every trust decision is an attack surface.
Bringing It Together: Monolith → Distributed
| Concept | Monolith (L19) | Distributed (L20) |
|---|---|---|
| Communication | Method calls (nanoseconds) | Network calls (milliseconds+) |
| Failure modes | Process crash → everything fails | Partial failures, network partitions |
| Consistency | DB transactions span all operations | Eventual consistency, no cross-service transactions (L33) |
| Debugging | Single stack trace, single log file | Distributed tracing, multiple log streams |
| Deployment | All-or-nothing | Independent service deploys |
| Scaling | Scale everything together | Scale services independently |
| Security | Internal method calls (implicit trust) | Every call across network (explicit auth) |
The monolith-first principle still holds. Don't distribute until you need to. When you do need to — for isolation, scaling, team autonomy, or platform leverage — you now understand what you're signing up for.
Conway's Law: Even More True for Distributed Systems
In L19, we introduced Conway's Law:
"Organizations which design systems are constrained to produce designs which are copies of the communication structures of those organizations."
— Melvin Conway, 1967
For distributed systems, this cuts both ways:
If your teams are siloed → your services will be siloed
Pawtograder: separate teams for the Grading Action, API, and Discord bot → separate services with clean interfaces.
If teams must coordinate constantly → services will be tightly coupled
Distributed monolith! Teams that can't deploy independently → services that can't deploy independently.
We'll explore this further in L22 (Teams and Collaboration).
What's Next: Serverless
In L21, we'll explore Serverless Architecture — an architectural style that pushes many of today's concerns to the platform level.
What serverless does:
- Infrastructure management → platform's job
- Scaling, availability → platform's job
- Some security concerns → platform's job
- You focus on business logic
The tradeoffs:
- You STILL deal with all eight fallacies
- You gain elasticity and scale-to-zero
- You lose control over runtime environment
- New constraints: cold starts, execution time limits
Pawtograder uses serverless extensively — Supabase Edge Functions, GitHub Actions.
Serverless is the natural continuation of today's lesson: it's distributed computing with operational complexity offloaded to the cloud provider.
Bonus Slide
