
CS 3100: Program Design and Implementation II
Lecture 21: Serverless Architecture
©2026 Jonathan Bell & Ellen Spertus, CC-BY-SA
Announcements
Late tokens CAN be used on group assignments.
- See details in link from syllabus.
Due Friday
- Midterm survey via Qualtrics
- Team formation survey
- Khoury mid-semester evaluation
Learning Objectives
After this lecture, you will be able to:
- Recognize common infrastructure building blocks (databases, queues, caches, object storage, observability) and their architectural roles
- Define "serverless" architecture and Functions as a Service (FaaS) concepts
- Compare serverless to traditional and container-based architectures, identifying tradeoffs
- Identify requirements that are well-suited or poorly-suited for serverless
- Apply a decision framework for choosing between architectural styles based on team size, scaling needs, and operational capacity
Important framing: You will encounter serverless systems in internships and jobs. The goal is to understand why teams choose serverless and reason about whether it fits a given problem — not to become a serverless architect overnight.
Poll: What's the fun part?
Imagine memes haven't been invented, and you decide to create the first meme generator and server. What will you want to spend your time on?
A. the GUI, including the meme editor
B. keeping search and retrieval fast with 10M memes
C. handling traffic when a meme goes viral
D. authenticating users securely
E. scrambling to fix production problems at 2 AM
F. diagnosing why memes randomly fail in Asia

Text espertus to 22333 if the
URL isn't working for you.
DIY or Cloud

The Infrastructure Iceberg
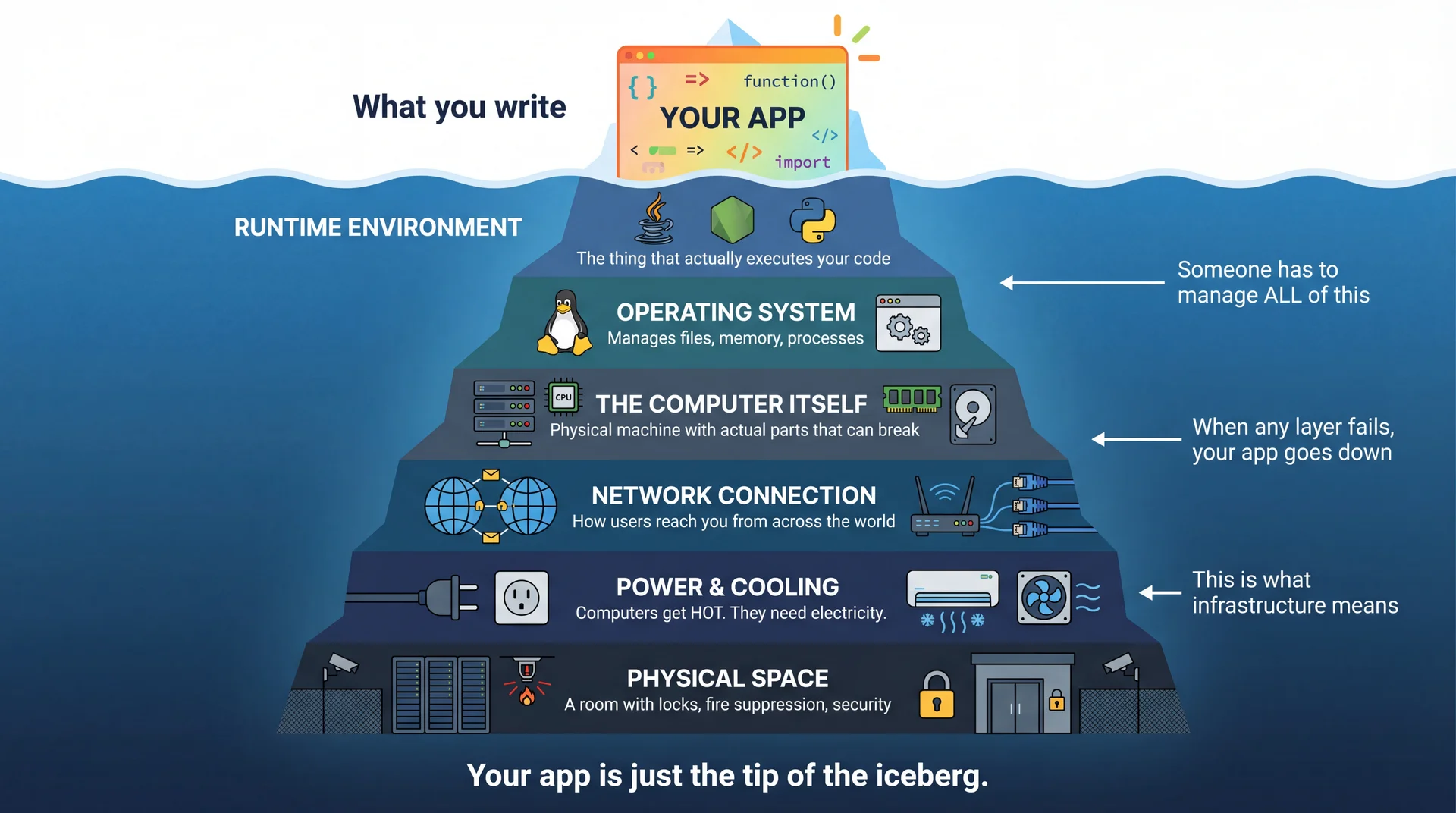
Storing Memes: We Need a Database and Object Storage
Every meme has metadata and an image that need to outlive your server process. A database gives you persistent storage for metadata.
PostgreSQL (relational)
memes
─────────────────────────────────────
id | 4821
template_id | 12
top_text | 'Me'
bottom_text | 'A new programming language'
author_id | 99
rating | 4.7
image_url | 'memes/4821.jpg'
Rows, columns, strict schema. Supports joins, aggregations, transactions, making it more suitable for our meme server.
Firestore (NoSQL)
{
"id": "meme_4821",
"template": "distracted-boyfriend",
"text": {
"top": "Me",
"bottom": "A new programming language"
},
"author": 99,
"rating": 4.7,
"image_url": "memes/4821.jpg"
}
Flexible JSON documents. Easy to add fields. No joins.
Images are stored separately in cheaper object storage.
Indexing: Finding Memes Without Reading Everything
With 10 million memes, you can't scan every row on every search. A database index is a pre-computed lookup structure — like a book's index, but rebuilt automatically as data changes.
Without index: full table scan
SELECT * FROM memes
WHERE top_text LIKE '%programming%'
OR bottom_text LIKE '%programming%';
Reads all 10M rows. Every search. Gets slower as library grows. Response time: seconds.
With index: direct lookup
-- Create a composite index over both text fields
CREATE INDEX memes_text_search
ON memes
USING gin(to_tsvector('english', top_text || ' ' || bottom_text));
-- Query using the index
SELECT * FROM memes
WHERE to_tsvector('english', top_text || ' ' || bottom_text)
@@ to_tsquery('english', 'programming');
Index narrows to matching rows instantly. Response time: milliseconds at any scale.
The database builds and maintains the index automatically. You declare what to index; it handles the rest.
Caching
When the same data is requested repeatedly, caching stores the result so you don't recompute it. Trade a little memory for a lot of speed.
Without cache
User → App → Database → App → User
↑ repeated 10,000×
for "drake meme" results
Each request pays the full query cost. Popular searches hammer the database.
With cache (Redis)
search:"drake meme" → [4821, 4799, 4755, ...]
template:12 → "templates/drake.jpg"
meme:4821 → { top_text: "Me", ... }
Results stored by key. First request hits the database; the next 9,999 are served from memory.
Select images (such as the most popular templates) can also be stored in memory.
Handling Traffic When a Meme Goes Viral
Your meme generator handles 100 requests/second on a normal day. Then your distracted boyfriend meme gets posted on Reddit. Suddenly: 100,000 requests/second. How do you not crash?
Without a queue: direct processing
100,000 users
↓
Your server
(built for 100)
↓
💥 crash
Requests pile up, server runs out of memory, everyone gets an error.
With a queue: buffered processing
100,000 users
↓
Message queue
(holds requests)
↓
Workers process
at sustainable pace
Requests are accepted immediately. Workers drain the queue as fast as they can. No crashes, no lost requests.
Common services: AWS SQS, Google Pub/Sub, RabbitMQ. Queues usually provide at-least-once delivery with retries/visibility timeouts; handlers should be idempotent, and poison messages should go to a dead-letter queue.
Authenticating Users Securely
Your meme generator needs to know who's who. Authentication is deceptively hard to get right — and the consequences of getting it wrong are severe.
What could go wrong?
- Passwords stored in plain text — one breach exposes everyone
- Weak session tokens — attackers can impersonate users
- No rate limiting — brute-force login attacks
- Forgotten password reset flaws — account takeover
- No MFA — stolen password = full access
What you actually need
- Secure password hashing (bcrypt, Argon2)
- Short-lived, signed session tokens (JWT)
- Rate limiting on login attempts
- Secure password reset flows
- Multi-factor authentication support
- OAuth ("Sign in with Google")
This is why teams use managed auth services. The attack surface is large, the stakes are high, and the requirements are well-understood. This is exactly the kind of problem best outsourced to specialists.
Monitoring and Alerting
Your meme generator is running in production. How do you catch problems before they blow up?
Without alerting
- Users notice before you do
- You find out via angry tweets
- You have no idea when it started
- You don't know how many users are affected
- You're guessing at the cause
With alerting
- Monitor key metrics: error rate, latency, queue depth
- Set thresholds: "page me if error rate exceeds 1%"
- Get notified before users do
- Know exactly when the problem started
- On-call rotation shares the burden
Common services: PagerDuty, Datadog, AWS CloudWatch. The goal is to be proactive — your monitoring catches the problem, not your users.
What you don't get paged about: disk failures, server reboots, OS upgrades, network outages, hardware replacements. The cloud handles these — you only get woken up for problems in your code.
Observability: Diagnosing Why Memes Fail in Asia
Alerting tells you something is wrong. Observability tells you why — even when the problem only affects some users, in some regions, some of the time.
Logs
A record of what happened
[ERROR] meme:4821 failed to load
region: ap-northeast-1
latency: 8200ms
cause: storage timeout
Metrics
Aggregated measurements over time
error_rate{region="asia"} 12%
error_rate{region="us"} 0.1%
p99_latency{region="asia"} 8s
p99_latency{region="us"} 120ms
Traces
The path of a single request
User request (8200ms total)
├─ Auth check 12ms
├─ Database query 45ms
└─ Image fetch 8100ms ⚠
└─ CDN miss → origin
(wrong region)
Without the trace, you might spend hours guessing. With it, the problem is obvious: images are being fetched from the wrong region. Common services: Datadog, Sentry, AWS CloudWatch.
Who configures this? The platform automatically captures infrastructure logs (server restarts, network errors, scaling events). You add application logs — the lines in your code that record what your meme generator is actually doing.
Offering an API: You Need a Gateway
Your meme generator is a hit. Developers want to build mobile apps, bots, and integrations on top of it. You decide to offer a public API. Every request needs auth, routing, and rate limiting — but you don't have to write any of it yourself.
Client request
↓
API Gateway
├─ Authenticate: is this a valid API key?
├─ Rate limit: has this client exceeded 100 requests/min?
├─ Route: /memes/* → meme service
│ /users/* → user service
│ /templates/* → template service
└─ Forward to your code
Without a gateway
Every service reimplements auth, rate limiting, and routing. Changes must be made everywhere. One misconfiguration exposes your entire backend.
With a gateway
One place to enforce policies. Backend services only see authenticated, routed requests. Add a new service without changing client code.
Common services: AWS API Gateway, Kong, Supabase. Configure policies in one place — your backend code never sees an unauthenticated or over-limit request.
Summary: Infrastructure Building Blocks
Cloud platforms provide standardized components that solve these recurring problems. Just as we have design patterns in code, these "building blocks" appear across architectural styles.
Databases
Structured data persistence
PostgreSQL, MongoDB, DynamoDB
Object Storage
Files and binary data at scale
S3, Cloud Storage, Supabase Storage
Message Queues
Async communication, buffering
SQS, Pub/Sub, RabbitMQ, pgmq
Caches
Fast access to hot data
Redis, Memcached, Upstash
API Gateways
Unified entry point, auth, routing
AWS API Gateway, Kong
Observability
Logs, metrics, traces
Sentry, Datadog, CloudWatch
Serverless architecture is fundamentally about composing these managed services: you write functions containing business logic; the cloud provider operates the infrastructure.
Your Meme Generator: Composed from Managed Services
You wrote the meme generation logic. Everything else? Managed services you composed together.
The purple box is what you write. Everything else is managed infrastructure — operated by specialists, scaled automatically, billed by usage.
The Cloud Deployment Spectrum
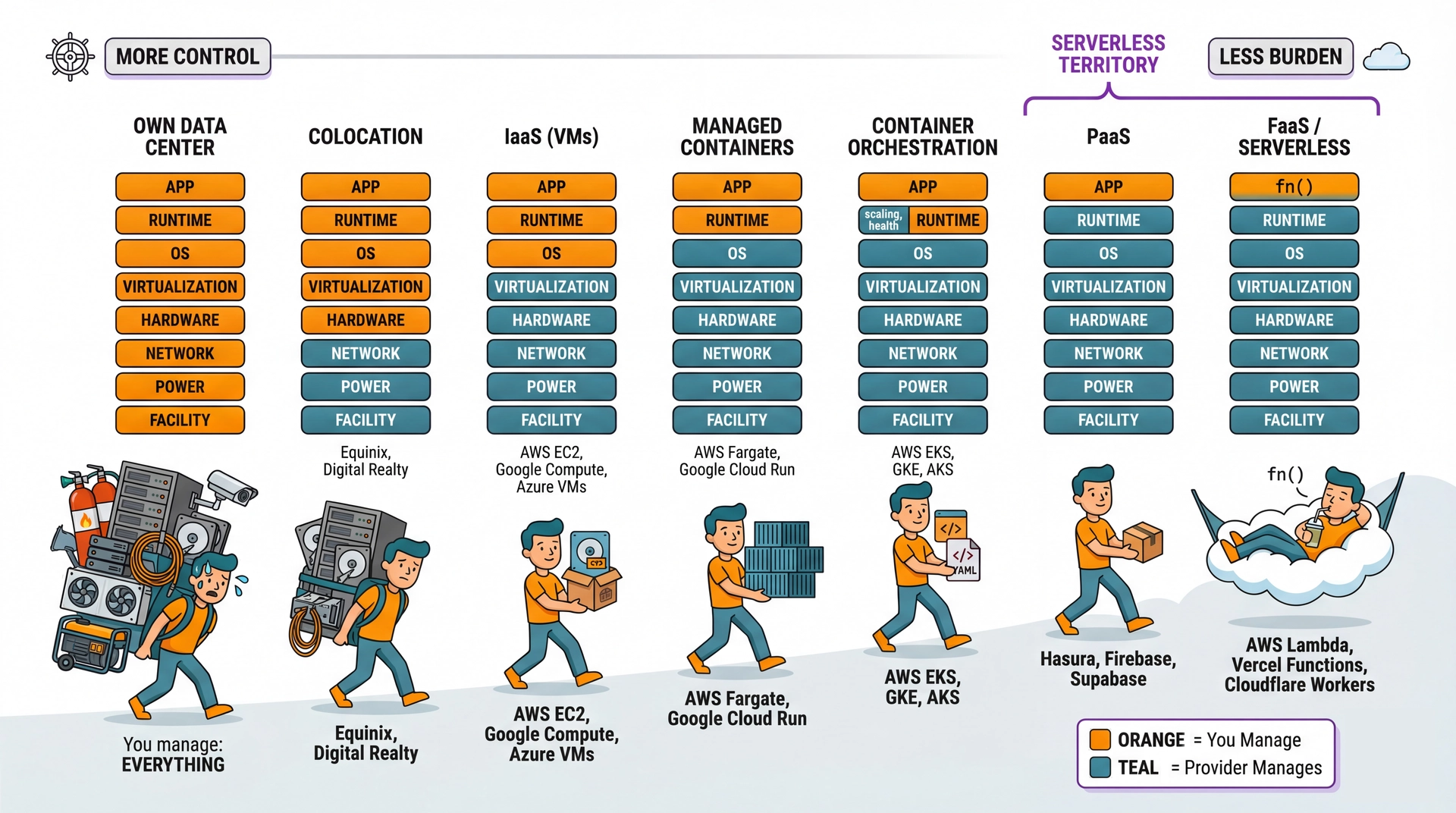
Not shown: SaaS (Software as a Service) — even further right.
What Is Serverless?
"Serverless" doesn't mean no servers. It means someone else manages them. You write code and compose managed services; the cloud provider handles everything beneath.
Traditional
- You provision servers
- You configure the OS and runtime
- You handle scaling and restarts
- You pay for idle time
- You get paged when hardware fails
Serverless
- Vendor provisions servers
- Vendor configures OS and runtime
- Vendor handles scaling and restarts
- You pay only for execution time
- Vendor gets paged when hardware fails
Your meme generator is already largely serverless — managed database, object storage, cache, queue, auth, and API gateway. The last piece: your own code. That's where Functions as a Service comes in.
Functions as a Service (FaaS)
Instead of a server running 24/7, you deploy functions that execute in response to events. No main(), no server setup — just your logic.
Meme generation function
public class GenerateMemeHandler
implements RequestHandler<APIGatewayProxyRequestEvent,
APIGatewayProxyResponseEvent> {
public APIGatewayProxyResponseEvent handleRequest(
APIGatewayProxyRequestEvent request,
Context context) {
MemeRequest body = parseJson(request.getBody());
byte[] template = storage.get(body.templateId());
byte[] meme = MemeUtils.addText(
template, body.topText(), body.bottomText());
String url = storage.put("memes/", meme);
db.insert(new Meme(body, url));
return ok(new MemeResponse(url));
}
}
Four key properties
① Event-driven Platform calls your function when an event arrives. You don't listen for requests.
② Stateless No state persists between calls. All state lives in external services.
③ Clear contract Request in, response out. Keep side effects explicit (e.g., DB/storage writes) and bounded.
④ Pay per invocation No requests? No cost. 1M requests? Billed for exactly that.
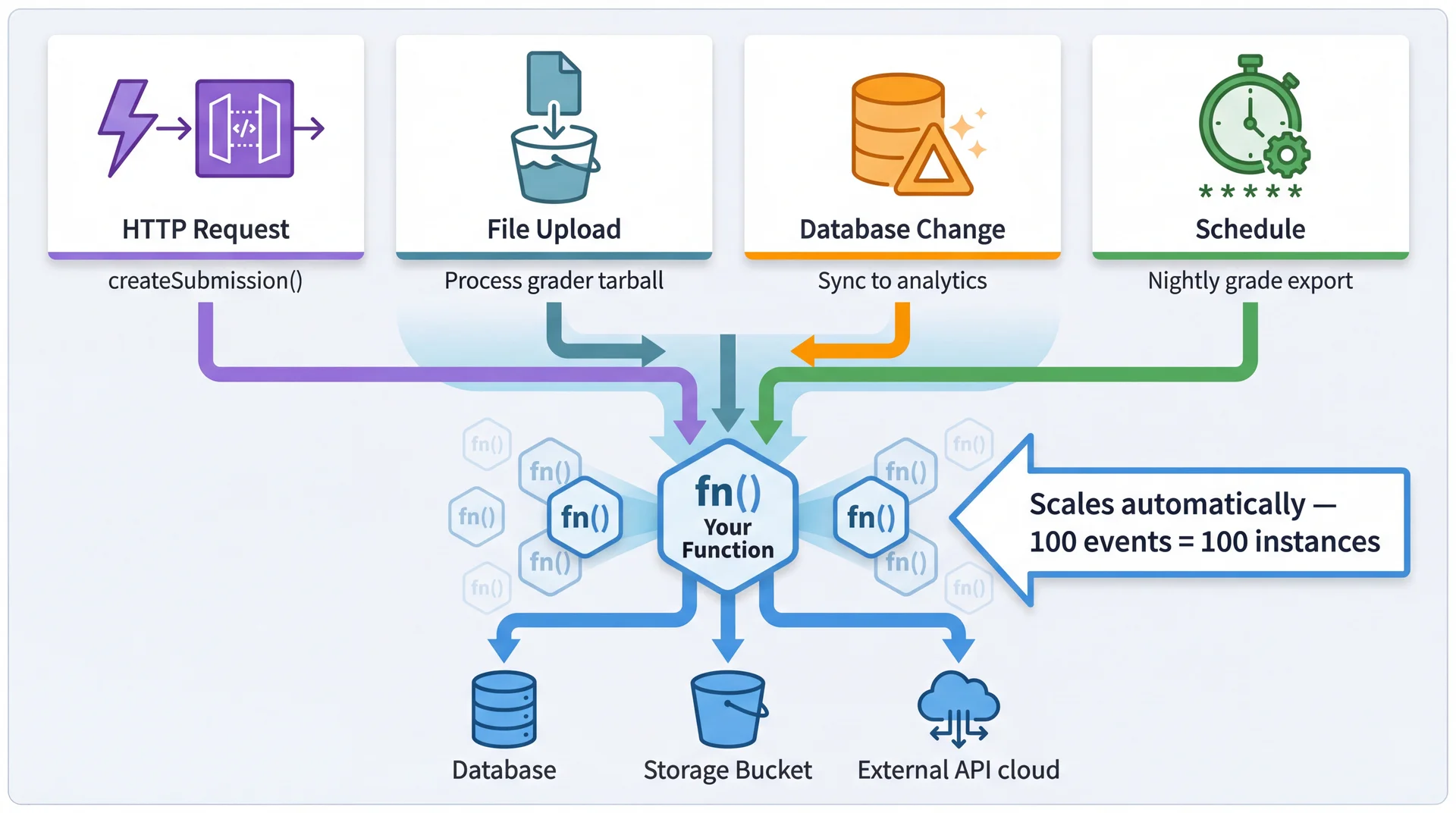
Event-Driven Execution
Serverless functions are triggered by events — not just HTTP requests. This enables reactive architectures where functions respond to changes in the system.
Energy Efficiency Considerations
Serverless architecture has interesting sustainability implications that cut both ways.
Potential Energy Savings
-
No idle power: Monolith runs 24/7 even at 3 AM. Serverless consumes energy only when executing.
-
Shared infrastructure: Cloud providers achieve high utilization across thousands of customers. 80% utilization > 10%.
-
Right-sized execution: Functions get exactly the resources needed (modulo startup overhead).
Potential Energy Costs
-
Cold start overhead: Spinning up new containers has energy costs warm monoliths avoid.
-
Per-request overhead: Each invocation goes through routing, logging, billing infrastructure.
-
Distributed chattiness: Many small functions calling each other = network energy costs.
The architectural lesson: batch operations when possible. Pawtograder's submitFeedback() sends all test results in one call, not 100 separate calls. This saves latency, cost, AND energy.
When Does Serverless Fit?
Bringing It Together: L19 → L20 → L21
| Lecture | Question | Key Insight |
|---|---|---|
| L19 | How do we organize code? | Architectural styles emerge from quality attribute requirements. Monolith-first is usually right. |
| L20 | What changes over networks? | The eight fallacies. Every network call can fail, be slow, or be intercepted. |
| L21 | What if someone else manages infra? | Serverless = technical partitioning with a vendor. Same principles, different operational model. |
The thread connecting all three:
Same design principles at every scale:
- Information hiding (L6)
- Coupling and cohesion (L7)
- Hexagonal architecture (L16)
- Quality attribute tradeoffs (L19)
The practical takeaway:
No single architecture is right for everything. Pawtograder's hybrid approach demonstrates this — serverless API, managed compute for grading, PostgreSQL for domain logic.
Same Questions, Every Scale
At every level — class, module, service, system — you ask the same four questions:
| Question | What It Determines |
|---|---|
| What changes independently? | Where to draw boundaries |
| Who needs to know? | What the interface should hide |
| What can fail? | How explicit your error handling must be |
| What are you trading? | Whether the tradeoff is worth it |
L6-L7
Classes & methods
Private fields, cohesive modules
L16-L18
Services & boundaries
Ports, adapters, APIs
L20
Network boundaries
Fallacies, failures, security
L21
Vendor boundaries
Managed infra, tradeoffs
The Architect's Toolkit
You now have a framework for approaching any system:
When you see a boundary, ask:
- What's hiding behind it?
- Who owns each side?
- What happens when communication fails?
When you're drawing a boundary, ask:
- What changes independently?
- Who needs to know about what?
- Is this a one-way door or two-way door?
When evaluating an architecture, ask:
- What quality attributes drove these choices?
- What tradeoffs were accepted?
- What would break if requirements changed?
When choosing complexity, ask:
- Do I have a specific problem this solves?
- Can I start simpler and evolve?
- What's the cost of being wrong?
The principles scale. The details change. The questions stay the same.
What's Next: Teams and Collaboration
We've been implicitly assuming a single developer making all decisions. Real software is built by teams — and team structure has a big impact on how software gets built.
L22: Teams and Collaboration
- How teams organize, communicate, coordinate
- Why org structure shapes system structure
- Architectural boundaries often become team boundaries
- Strategies for effective collaboration
The connection:
Today we saw serverless as outsourcing infrastructure to a specialist vendor — your team focuses on domain logic, they focus on infra.
That's an organizational decision as much as a technical one.
Bonus Slide
